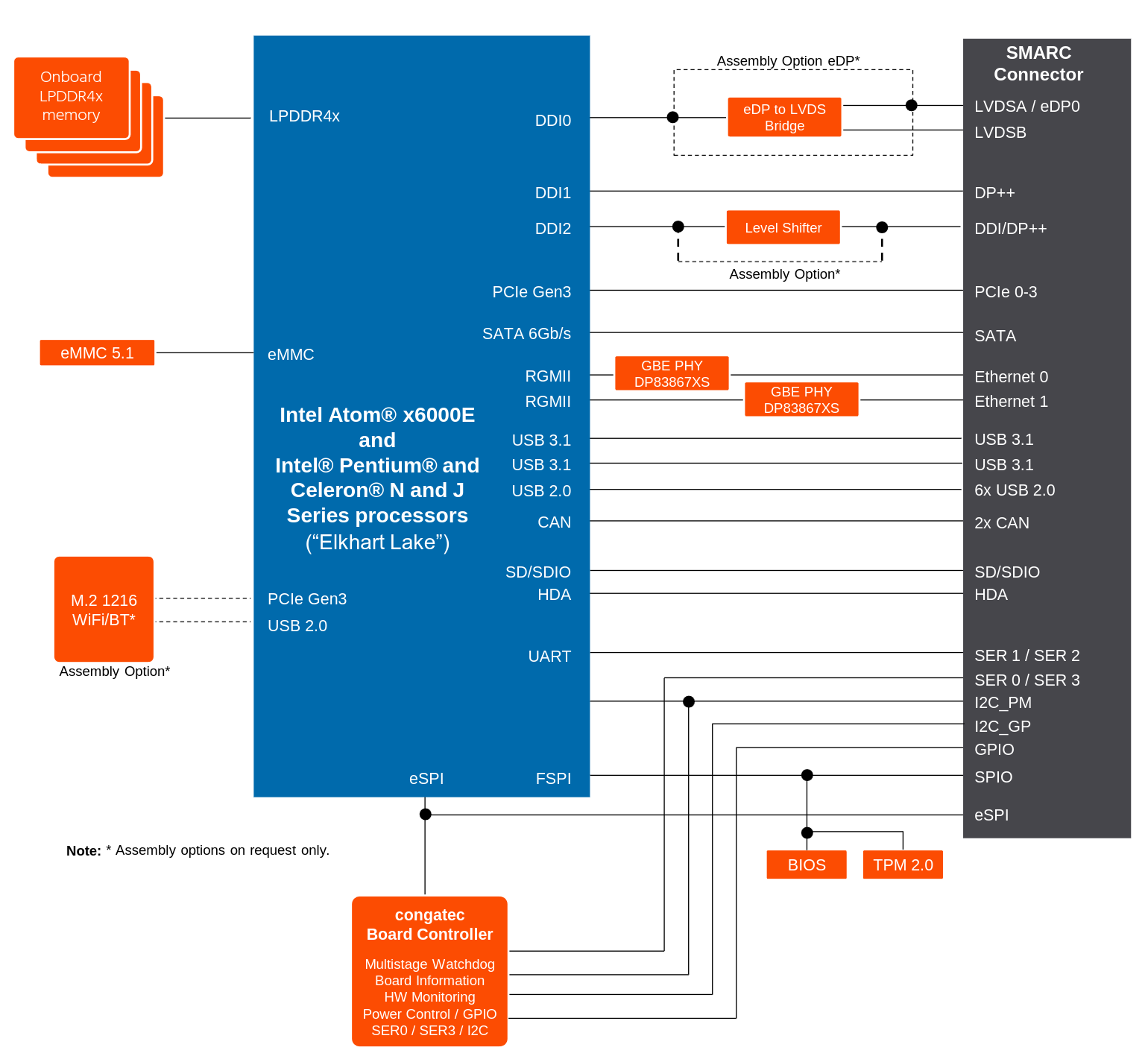
Capitole du Libre is the leading annual open-source and free software conference in Toulouse, France, and has been a key event in the community for over a decade. With offices based in Toulouse, Bootlin has been a long-time participant and active contributor to this event, and 2025 will be no exception.
Capitole du Libre is the leading annual open-source and free software conference in Toulouse, France, and has been a key event in the community for over a decade. With offices based in Toulouse, Bootlin has been a long-time participant and active contributor to this event, and 2025 will be no exception.
- Bootlin is part of the 4 Platine sponsors of the event, the highest sponsorship level
- Bootlin will have a booth in the main hall of the conference, which will allow visitors to meet the Bootlin team, discuss Bootlin activities, career and internship opportunities, and more
- Bootlin engineers will be giving a number of talks, related to Embedded Linux or not:
- Thomas Petazzoni will be giving a talk titled What’s new in the Linux kernel: a year of changes in review
- Alexis Lothoré and Maxime Chevallier will be delivering a hands-on workshop on Mastering eBPF and XDP: creating a high-performance ad blocker
- The same Alexis Lothoré will be talking about a more personal project: An Open-Source Blind Test from Start to Finish: When Free Software Makes Our Parties Buzz
Looking forward to meet you at Capitole du Libre in November!

 Linux 6.17
Linux 6.17