When the compressed and uncompressed kernel images overlap
At least on ARM32, there seems to be many working addresses where the compressed kernel can be loaded in RAM. For example, one can load the compressed kernel at offset 0x1000000 (16 MB) from the start of RAM, and the Device Tree Blog (DTB) at offset 0x2000000 (32 MB). Whatever this loading address, the kernel is then decompressed at offset 0x8000 from the start of RAM, as explained this the famous How the ARM32 Linux kernel decompresses article from Linus Walleij.
There is a potential issue with the loading address of the compressed kernel, as explained in the article too. If the compressed kernel is loaded too close to the beginning of RAM, where the kernel must be decompressed, there will be an overlap between the two. The decompressed kernel will overwrite the compressed one, potentially breaking the decompression process.
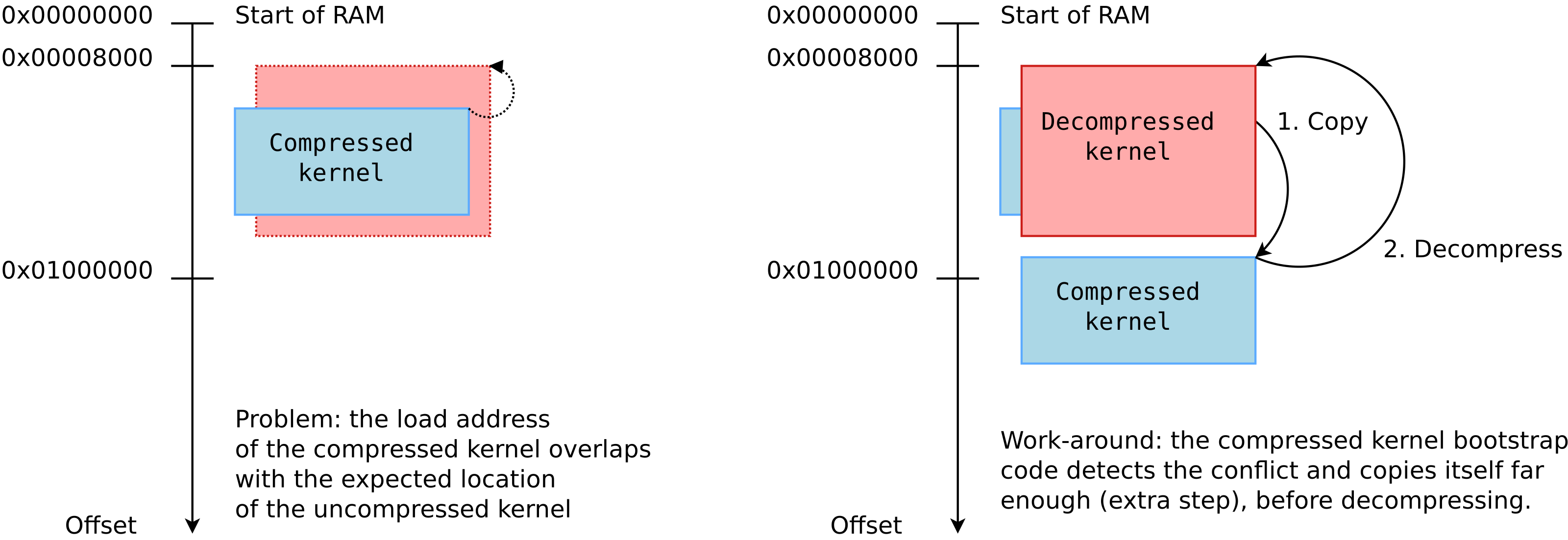
As you see in the above diagram, when this happens, the bootstrap code in the compressed kernel will first copy the compressed image to a location that’s far enough to guarantee that the decompressed kernel won’t overlap it. However, this extra step in the boot process has a cost.
Measuring boot time impact
In the context of updating our materials for our upcoming Embedded Linux Boot Time Optimization course in June, we measured this additional time on the STM32MP157A-DK1 Discovery Kit from STMicroelectronics, with a dual-core ARM Cortex-A7 CPU running at 650 MHz.
Initially, in our Embedded Linux System Development course, we were booting the DK1 board as follows:
ext4load mmc 0:4 0xc0000000 zImage; ext4load mmc 0:4 0xc4000000 dtb; bootz 0xc0000000 - 0xc4000000
0xc0000000 is exactly the beginning of RAM! We are therefore in the overlap situation.
We used grabserial from Tim Bird to measure the time between Starting kernel in U-Boot and when the compressed kernel starts executing (Booting Linux on physical CPU 0x0):
... [4.451996 0.000124] Starting kernel ... [0.001838 0.001838] [2.439980 2.438142] [ 0.000000] Booting Linux on physical CPU 0x0 ...
On a series of 5 identical tests, we obtained an average time of 2,440 ms, with a standard deviation of 0.4 ms.
Then, we measured the optimum case, in which the compressed kernel is loaded far enough from the beginning of RAM so that no overlap is possible:
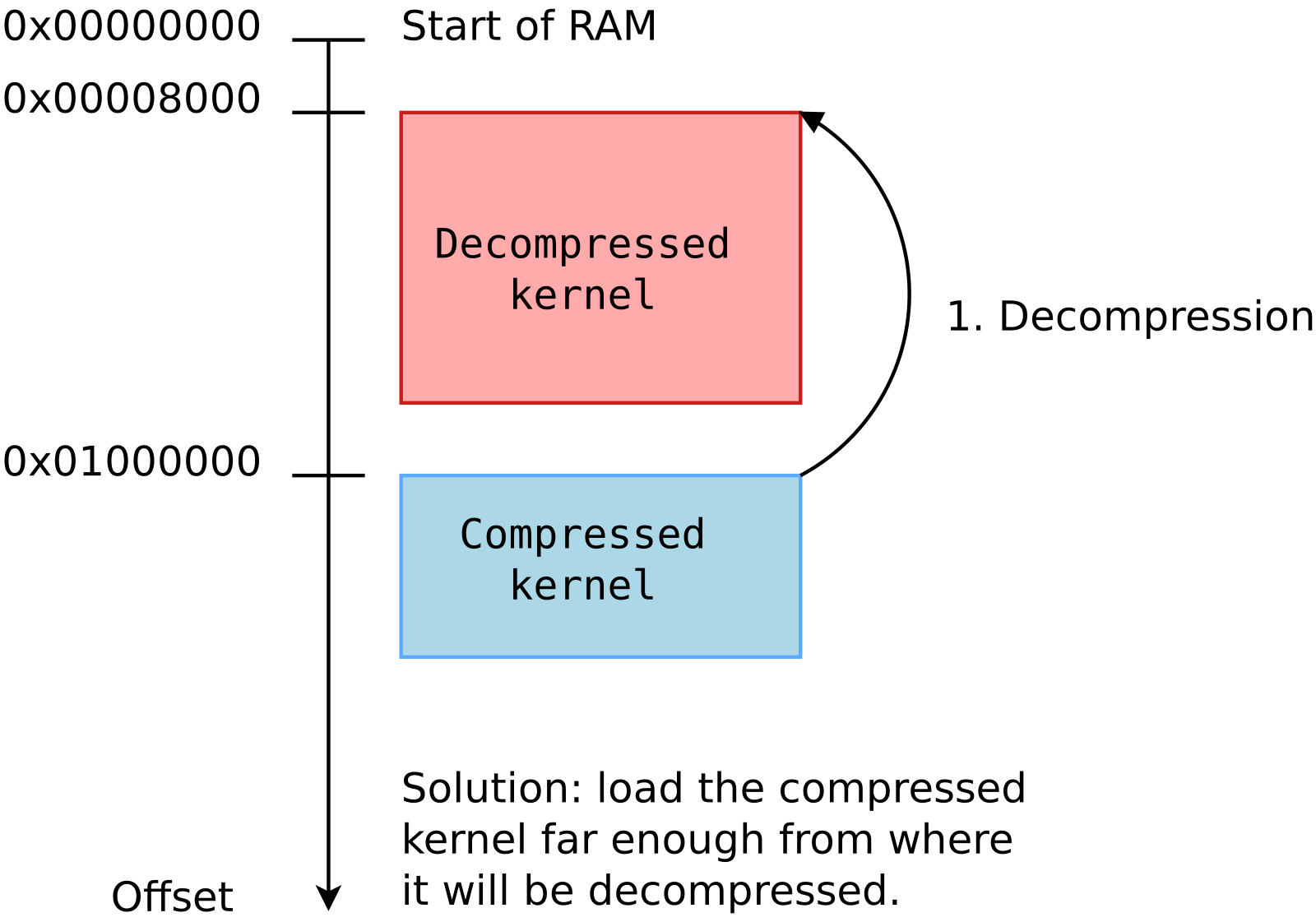
Here we chose to load the kernel at 0xc2000000:
ext4load mmc 0:4 0xc2000000 zImage; ext4load mmc 0:4 0xc4000000 dtb; bootz 0xc2000000 - 0xc4000000
On a series of 5 identical tests, we obtained an average time of 2,333 ms, with a standard deviation of 0.7 ms.
The new average is 107 ms smaller, which you are likely to consider as a worthy reduction, if you have experience with boot time reduction projects.
What to remember
In your embedded projects, if you are using a compressed kernel, make sure it is loaded far enough from the beginning of RAM, leaving enough space for the decompressed kernel to fit in between. Otherwise, your system will still be able to boot, but depending on the speed of your CPU and storage, it will be slower, from a few tens to a few hundreds of milliseconds.
We checked the How to optimize the boot time page on the STM32 wiki, and it recommends optimum loading addresses: 0xc2000000 for the kernel and 0xc4000000 for the device tree. This way, the upper limit for the decompressed kernel is 32 MB, which is more than enough.
If you are directly using an uncompressed kernel, which is more rare, you should also make sure that it is loaded at an optimum location, so that there is no need to move it before starting it.