 Even if the presence of Rust is slowly increasing in the Linux kernel code base, the project largely remains written in C, and while this is the de facto language to write low level code, it unfortunately also comes with a significant ability of making mistakes, with the corresponding failures then coming in a wide variety of shapes: undefined behaviors, buffer overflows, segmentation faults… The kernel is not immune to such issues, and so kernel developers need some dedicated tooling to catch those issues early. As many problems have their roots in memory management, one tool that can legitimately sit in any kernel hacker toolbox is the Kernel Address Sanitizer, or KASAN for short. This blog does not aim to teach readers how to use KASAN: the kernel documentation is pretty explicit on this matter. We are rather going to explore KASAN internals, mostly to understand its impact (both at build time and at runtime), but up to some extent, to appreciate the elegant engineering involved in its implementation!
Even if the presence of Rust is slowly increasing in the Linux kernel code base, the project largely remains written in C, and while this is the de facto language to write low level code, it unfortunately also comes with a significant ability of making mistakes, with the corresponding failures then coming in a wide variety of shapes: undefined behaviors, buffer overflows, segmentation faults… The kernel is not immune to such issues, and so kernel developers need some dedicated tooling to catch those issues early. As many problems have their roots in memory management, one tool that can legitimately sit in any kernel hacker toolbox is the Kernel Address Sanitizer, or KASAN for short. This blog does not aim to teach readers how to use KASAN: the kernel documentation is pretty explicit on this matter. We are rather going to explore KASAN internals, mostly to understand its impact (both at build time and at runtime), but up to some extent, to appreciate the elegant engineering involved in its implementation!
Continue reading “Poison, redzones and shadows: inside KASAN”
 As part of a project I am currently working on at Bootlin, I had the opportunity to attend the
As part of a project I am currently working on at Bootlin, I had the opportunity to attend the  earlier this week
earlier this week

 Linux 7.0
Linux 7.0 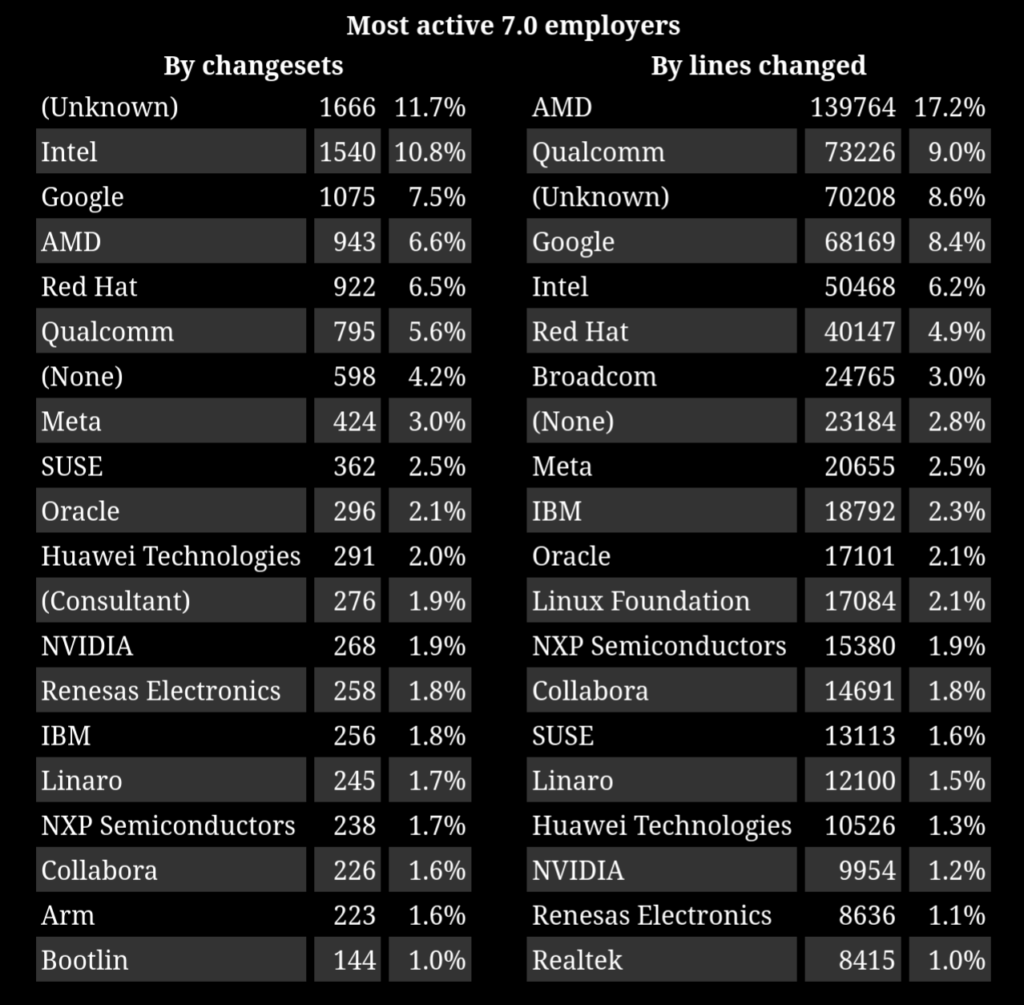
 Linux 6.19 was
Linux 6.19 was 
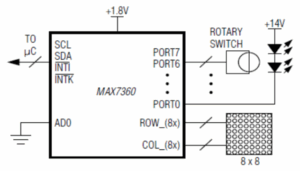 Among all activities I’ve been doing at Bootlin during the past few months, one has been to add support for the
Among all activities I’ve been doing at Bootlin during the past few months, one has been to add support for the