 Bootlin is happy to share that our engineer Luca Ceresoli will be speaking at Linux Day 2025 in Bergamo, Italy, on Saturday, October 25, 2025.
Bootlin is happy to share that our engineer Luca Ceresoli will be speaking at Linux Day 2025 in Bergamo, Italy, on Saturday, October 25, 2025.
Luca’s talk, titled “Software updates on embedded Linux devices” (“Aggiornamenti software su dispositivi embedded Linux”), will take place from 14:00 to 15:00.
About the talk
Many of the electronic products we use every day are powered by Linux, even when we don’t see it. Like PCs, these embedded devices also need software updates to fix bugs and improve functionality. However, unlike PCs, they must perform these updates automatically and reliably, without any user intervention.
In his presentation, Luca will explain one of the most widely used techniques for achieving this: A/B updates. He will describe what they are, how they work, and the most common tools used to implement them in embedded Linux systems.
This talk is a great opportunity for developers and engineers interested in the practical challenges of maintaining and updating Linux-based devices in the field.
About Linux Day
Linux Day is an annual, nationwide event organized across Italy to promote the use and understanding of free and open-source software. Many cities host talks, workshops, and meetups aimed at both newcomers and experienced developers. The Bergamo edition continues this tradition with a full day of technical sessions, community engagement and an install party.
Meet Luca and Bootlin
If you’re attending Linux Day Bergamo 2025, don’t miss Luca’s session! Don’t hesitate to meet Luca to talk about what we do at Bootlin and open job positions!
 Back in December 2025, we announced the release of sbom-cve-check, a lightweight CVE analysis tool for your Software Bill of Materials (SBOM).
Back in December 2025, we announced the release of sbom-cve-check, a lightweight CVE analysis tool for your Software Bill of Materials (SBOM). Linux 6.19 was
Linux 6.19 was 
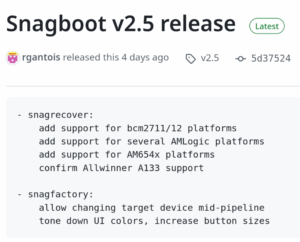
 Bootlin has recently contributed to the
Bootlin has recently contributed to the 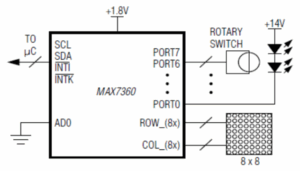 Among all activities I’ve been doing at Bootlin during the past few months, one has been to add support for the
Among all activities I’ve been doing at Bootlin during the past few months, one has been to add support for the