 Back in December 2025, we announced the release of sbom-cve-check, a lightweight CVE analysis tool for your Software Bill of Materials (SBOM). Since the announcement, we have announced a number of updates and new releases, but work has continued, and we have several new updates to share about sbom-cve-check.
Back in December 2025, we announced the release of sbom-cve-check, a lightweight CVE analysis tool for your Software Bill of Materials (SBOM). Since the announcement, we have announced a number of updates and new releases, but work has continued, and we have several new updates to share about sbom-cve-check.
Category: Technical
Yocto Wrynose released, Bootlin contributions inside
 Yocto Wrynose 6.0 is now released. This is the new Long Term Support release of the Yocto Project and will be maintained until 2030. Bootlin is a very active contributor to the Yocto Project, most notably with Antonin Godard being the official Yocto Project documentation maintainer, and Mathieu Dubois-Briand being a core member of the Yocto SWAT team, but also with other Bootlin engineers who use and deploy Yocto to create optimized and long-term maintainable Linux systems for the embedded devices of our customers. This 6.0 release was no exception, and we were again very active in this release cycle, with over 300 commits authored by Bootlin engineers.
Yocto Wrynose 6.0 is now released. This is the new Long Term Support release of the Yocto Project and will be maintained until 2030. Bootlin is a very active contributor to the Yocto Project, most notably with Antonin Godard being the official Yocto Project documentation maintainer, and Mathieu Dubois-Briand being a core member of the Yocto SWAT team, but also with other Bootlin engineers who use and deploy Yocto to create optimized and long-term maintainable Linux systems for the embedded devices of our customers. This 6.0 release was no exception, and we were again very active in this release cycle, with over 300 commits authored by Bootlin engineers.
Continue reading “Yocto Wrynose released, Bootlin contributions inside”
Bootlin engineer Alexis Lothoré invited at the Linux Storage Filesystem & Memory Management & BPF Summit
 The Linux Storage, Filesystem, Memory Management & BPF Summit (LSFMMBPF) brings together leading developers, researchers, and Linux kernel subsystem maintainers to discuss, design, and implement improvements to the filesystem, storage, and memory management subsystems. The work initiated at this event typically makes its way into the mainline kernel and Linux distributions within the following 24 to 48 months.
The Linux Storage, Filesystem, Memory Management & BPF Summit (LSFMMBPF) brings together leading developers, researchers, and Linux kernel subsystem maintainers to discuss, design, and implement improvements to the filesystem, storage, and memory management subsystems. The work initiated at this event typically makes its way into the mainline kernel and Linux distributions within the following 24 to 48 months.
In the context of the partnership between Bootlin, the eBPF Foundation and the Alpha Omega organization, Bootlin engineer Alexis Lothoré is currently working on adding KASAN memory checker support to the eBPF subsystem: this work aims to make it easier for eBPF subsystem developers to catch (early) bugs that could be introduced in complex parts of the kernel, like in the eBPF verifier.
This work has already led to some initial design discussions and proof of concept implementation on the kernel mailing lists, but as it requires some close collaboration with kernel developers and maintainers, Alexis has also been invited to attend LSFMMBPF 2026, taking place from May 4th to May 6th in Zagreb, Croatia, and will present his ongoing work on “Adding KASAN support for JITed programs”. This will be the opportunity to discuss and iron out the roadblocks and details to get the feature integrated in the kernel, as this event is not really a classic conference in which people primarily attend talks: the goal really is to trigger discussions to make solutions and features move forward in the kernel, in a “workshop-like” atmosphere. This work is one among many others on-going topics in the Linux kernel that need discussions, more details are available in the full event schedule.
We are proud to have one of our engineers contributing to this gathering of Linux kernel experts. This invitation highlights Bootlin’s strong involvement in upstream Linux kernel development.
Bootlin training courses on NXP i.MX93 FRDM, and NXP Registered Partner status
 Bootlin’s training courses, along with our freely available training materials, have been a cornerstone of the embedded Linux ecosystem for over 20 years. During this time, we have continuously expanded and refined our training portfolio, both to cover new technical topics and to adopt new hardware platforms for our practical lab sessions.
Bootlin’s training courses, along with our freely available training materials, have been a cornerstone of the embedded Linux ecosystem for over 20 years. During this time, we have continuously expanded and refined our training portfolio, both to cover new technical topics and to adopt new hardware platforms for our practical lab sessions.
Today, we are excited to share two closely related milestones: the availability of our major training courses on an NXP platform, and Bootlin becoming an official NXP Registered Partner. These two developments reflect our long-standing collaboration with NXP technologies and our commitment to supporting engineers working with i.MX platforms.
 As part of our ongoing effort to improve and modernize our training offering, our three most popular training courses are now available on the NXP i.MX93 FRDM platform:
As part of our ongoing effort to improve and modernize our training offering, our three most popular training courses are now available on the NXP i.MX93 FRDM platform:
- Embedded Linux System Development
- Linux Kernel Driver Development
- Yocto Project and OpenEmbedded System Development
These courses are available immediately, and the corresponding training materials have already been published and can be freely accessed on our website. As usual, the courses can be delivered as public online sessions, private online sessions, or private on-site sessions, depending on your needs. If you are interested in attending one of these training sessions, or in organizing a private training for your team on the NXP i.MX93 FRDM platform, feel free to contact us to discuss your needs or consult our training schedule for upcoming public sessions.
Beyond training, Bootlin’s core business is providing engineering services to help organizations worldwide design and build products based on embedded Linux. Over the years, we have supported a large number of customers using NXP-based platforms—including i.MX6, i.MX7, i.MX8, and i.MX9, across a wide range of topics such as board bring-up, Linux BSP development, Linux kernel porting and driver development, Yocto Project or Buildroot integration, secure boot, and more.
Our new status as an NXP Registered Partner formally recognizes this extensive experience and collaboration. It also reinforces our ability to support customers with up-to-date expertise on NXP technologies, from early platform evaluation to production-ready systems. Check out our NXP partner page for more details on our expertise and offering related to NXP products.
In this context, making the NXP i.MX93 FRDM board a first-class platform for our training courses is a natural step. It allows engineers to train on modern NXP hardware that closely matches what they use in real-world projects, making the learning experience more practical and immediately applicable.
Linux PTP mainline development war story and new features
A few years ago, one of our customers came to us with what sounded like a reasonably straightforward request: adding support for the Precision Time Protocol to an existing Linux kernel Ethernet PHY driver, namely the Marvell PHY driver.
Not only this sounded reasonably easy, but someone had actually already done the work: Russell King, a famous Linux kernel developer, maintainer of the ARM 32-bit support and prolific contributor to the networking subsystem, had already sent to the netdev mailing list a patch series implementing exactly this. With this existing series, we initially expected that a few review rounds and some testing would be enough to get it merged. Task done, move on.
It turned out to be much more complicated.
We started this work in March 2023. Three years later, we only have posted a second revision of the Marvell PHY PTP support, and that happened only after a significant change to the PTP core API. Read on for a deep dive into this real-life story of Linux kernel development and contribution.
Continue reading “Linux PTP mainline development war story and new features”
Linux 7.0 released, Bootlin contributions inside
 Linux 7.0 was released earlier this week, and as usual we refer our readers to the excellent LWN articles that cover the major features brought by this new kernel version: part 1, part 2. We strongly encourage our readers to check out these articles, and we also recommend becoming an LWN.net subscriber to support their outstanding work documenting the Linux and open-source ecosystem.
Linux 7.0 was released earlier this week, and as usual we refer our readers to the excellent LWN articles that cover the major features brought by this new kernel version: part 1, part 2. We strongly encourage our readers to check out these articles, and we also recommend becoming an LWN.net subscriber to support their outstanding work documenting the Linux and open-source ecosystem.
Bootlin has also been very active in this Linux 7.0 release cycle, with 144 commits authored by Bootlin engineers in this release, placing us 17th among contributing organizations according to the Linux Kernel Patch Statistics, also putting Bootlin in the most active employers for Linux 7.0 according to LWN.net:
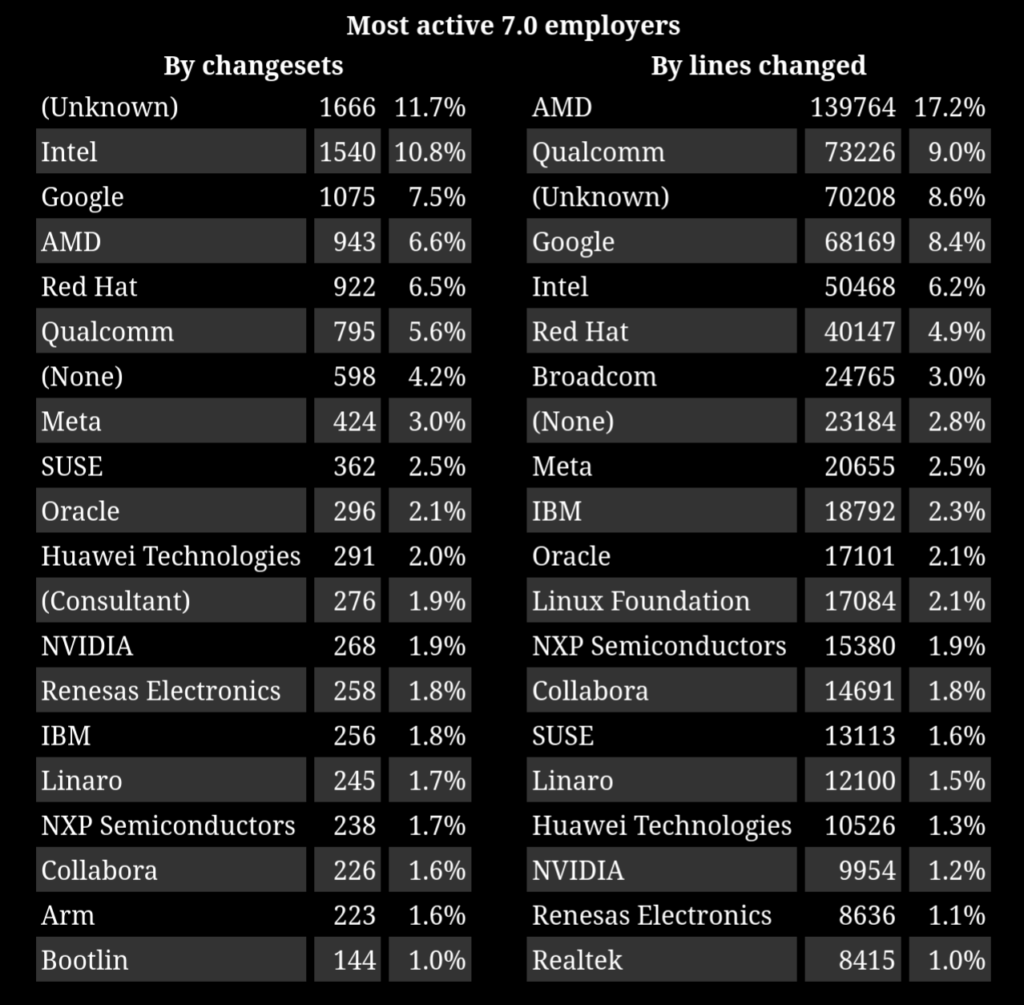
Also, in addition to authoring 144 commits, Bootlin engineers reviewed/merged 152 patches from other contributors: as the RTC and I3C subsystem maintainer, Alexandre Belloni merged 88 patches from other contributors, as the MTD subsystem co-maintainer, Miquèl Raynal merged 47 patches from other maintainers, Luca Ceresoli as a drm-misc co-maintainer merged 9 patches, and Grégory Clement as the Marvell platform maintainer merged 8 patches.
Continue reading “Linux 7.0 released, Bootlin contributions inside”
Announcing “Embedded Linux Security”, Bootlin’s brand new training course
 It is no mystery that cyber-security has become a highly important if not critical topic over the past few years. This naturally extends to embedded devices, including those running Linux and open-source software. For many years, Bootlin has been supporting its customers in implementing security features in embedded products: secure boot, encryption, Trusted Execution Environments, and more. We also help maintain Linux systems over time through CVE monitoring, long-term maintenance, and regular upgrades of Linux BSP components.
It is no mystery that cyber-security has become a highly important if not critical topic over the past few years. This naturally extends to embedded devices, including those running Linux and open-source software. For many years, Bootlin has been supporting its customers in implementing security features in embedded products: secure boot, encryption, Trusted Execution Environments, and more. We also help maintain Linux systems over time through CVE monitoring, long-term maintenance, and regular upgrades of Linux BSP components.
However, Bootlin’s DNA has never been limited to providing engineering services where we simply “do the work” for our customers. Sharing knowledge and empowering engineers to build and maintain their own systems is at the core of what we do.
Based on this philosophy and our security expertise, we are excited to announce a brand new training course: Embedded Linux Security.
 This course covers a wide range of topics essential to securing Linux-based embedded devices: fundamental security concepts, hardware-enforced security mechanisms, secure boot, data confidentiality and encryption, key management, user-space security, measured boot, system maintenance, regulatory compliance, and secure update strategies. We have brought together all the key building blocks needed to design and maintain a secure embedded Linux system in a single, comprehensive course. You can review the complete training agenda for full details.
This course covers a wide range of topics essential to securing Linux-based embedded devices: fundamental security concepts, hardware-enforced security mechanisms, secure boot, data confidentiality and encryption, key management, user-space security, measured boot, system maintenance, regulatory compliance, and secure update strategies. We have brought together all the key building blocks needed to design and maintain a secure embedded Linux system in a single, comprehensive course. You can review the complete training agenda for full details.
Our launch customer for this course is EBV Elektronik, for whom we will deliver the very first session in Spain mid-May. In line with Bootlin’s open-source culture, we will publish the complete training materials, free of charge and under an open-source license, shortly after this first session, adding them to the materials of our nine other training courses already freely available.
 Like most of our training courses, this one combines lectures with practical labs. The lectures are hardware-agnostic, providing knowledge applicable across platforms, with a natural focus on ARM-based systems. For the hands-on labs, we use the NXP i.MX93 FRDM, a platform offering strong security features and solid upstream software support.
Like most of our training courses, this one combines lectures with practical labs. The lectures are hardware-agnostic, providing knowledge applicable across platforms, with a natural focus on ARM-based systems. For the hands-on labs, we use the NXP i.MX93 FRDM, a platform offering strong security features and solid upstream software support.
If you are interested in attending this course, several options are available:
- Join one of our first public online sessions, delivered by the Bootlin engineers who designed the course:
- June 29 to July 3, from 2 PM to 6 PM (UTC+2), delivered by Mathieu Dubois-Briand. Register online – 899 EUR (early rate) / 999 EUR (standard rate)
- July 6 to July 10, from 2 PM to 6 PM (UTC+2), delivered by Olivier Benjamin. Register online – 899 EUR (early rate) / 999 EUR (standard rate)
- Organize a private in-person session at your location – contact us
- Organize a private online session dedicated to your team – contact us
We hope this new training will be useful to engineers and teams working on securing their embedded Linux systems, whether they are just getting started or already tackling advanced topics. We also hope to see many of our readers join one of the upcoming sessions, and we look forward to your feedback on this new course!
sbom-cve-check v1.2.0 released
We are pleased to announce the release of sbom-cve-check v1.2.0, which focuses on offline usability, improved SPDX 3.0 support, and more flexible export options.
For the record, sbom-cve-check is a lightweight, standalone and easy-to-use tool that parses Software Bill Of Materials (SBOM) files and using publicly available databases of security vulnerabilities (CVEs), provides a report detailing which software components are affected by known security vulnerabilities. sbom-cve-check is developed and maintained by Bootlin engineer Benjamin Robin.
In the next sections we will describe the major updates brought by this 1.2.0 release.
Snagboot v2.6 released: documentation, reliability, extended hardware support
 We are pleased to announce the release of Snagboot v2.6, bringing a set of improvements that make the tool more robust, easier to use, and more versatile across platforms. For those not familiar with Snagboot, it is an open-source and generic replacement to the vendor-specific, sometimes proprietary, tools used to recover and/or reflash embedded platforms.
We are pleased to announce the release of Snagboot v2.6, bringing a set of improvements that make the tool more robust, easier to use, and more versatile across platforms. For those not familiar with Snagboot, it is an open-source and generic replacement to the vendor-specific, sometimes proprietary, tools used to recover and/or reflash embedded platforms.
This new release 2.6 focuses on three main areas: documentation, reliability, and extended hardware support.
Continue reading “Snagboot v2.6 released: documentation, reliability, extended hardware support”
Embedded Recipes 2026: Chef sponsor, 19 engineers from Bootlin, registration open
 The Embedded Recipes conference is coming back to Nice for the second year, and it will take place on May 27 and 28!
The Embedded Recipes conference is coming back to Nice for the second year, and it will take place on May 27 and 28!
This community-driven event, with a unique format of a single track conference, really stands out compared to other events. To support this great initiative and for the second year in a row, Bootlin has decided to be first Chef Sponsor of the event.
A significant part of the Bootlin team will make the trip to Nice for this conference, as 19 engineers from our team will be attending. The registration is now open, and we recommend that you book your ticket early, as the number of seats is limited.
Even though the schedule for the conference has not been published yet, Bootlin CEO Thomas Petazzoni is part of the program committee for the event, and considering the high-quality submissions that were made through the Call For Papers, there is absolutely no doubt that the line-up of talks will be excellent.
In addition to the Embedded Recipes conference itself, a large number of co-located events are organized around this main event, forming the so-called Embedded Week. Already announced as co-located events:
- Buildroot Hackathon, May 29-31
- Linux Media Summit, May 26
- Pipewire Hackfest, May 29-30
- Bluez Face-To-Face, May 30-31
- Yocto Project Developer Day, May 29
- Display Next Hackfest, May 29-31
Essentially, if you’re an embedded Linux person, and you’re not in Nice on the week of May 26-31, you’re missing out on very good content, discussions and meetings! Book your seat and trip now, and join us at Embedded Recipes!