A few months ago, Bootlin released Snagboot, an open-source and generic replacement to the vendor-specific, sometimes proprietary, tools used to recover and reflash embedded platforms. This has led us to design recovery processes over USB for several different SoC families.
Our goal for each recovery process was the following: be able to upload U-Boot in external RAM and run it without modifying any non-volatile memories. Implementing this for many different platforms was challenging, as each vendor used different protocols, bootloader binaries, and methods to boot from recovery mode. Moreover, it was critical that the recovery tool be as user-friendly as possible, not requiring any complex configuration or vendor-specific workflows. This blog post describes the strangest recovery process we had to support so far: the one provided over USB by the Texas Instruments AM335x SoC.
Initializing AM335x platforms
When booted, each SoC has a specific sequence of actions it performs to load and run a target operating system or bare-metal program. This sequence typically starts with a ROM code, stored in a non-volatile internal memory. The main job of a ROM code is to search for a first-stage bootloader in various external memories and load it to internal RAM. In the case of AM335x platforms, this initialization sequence is described in the TI reference manual.
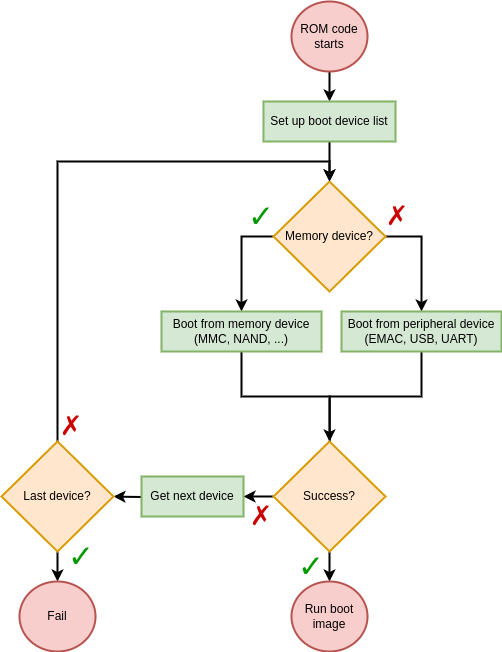
As we can see, there is nothing too outlandish here. The ROM code checks each device in its boot sequence and attempts to boot from it. What is particularly interesting to us here is the Boot from peripheral device part. Indeed, our ultimate goal is to send U-Boot to the SoC over a USB connection. So we will now dig a little further into this peripheral boot feature. The reference manual states that the AM335x ROM code is capable of booting from three types of peripheral interfaces: EMAC (Ethernet), USB and UART. Considering what we said earlier, what really interests us here is the USB boot feature. The USB boot procedure is described in more detail in the reference manual. And this is where things get a little strange.
Most ROM codes we’ve encountered use fairly simple vendor protocols to communicate over USB. You’ll typically find some memory read/write operations, some run operations, and maybe a few vendor-specific commands. The AM335x ROM code however, uses network protocols to boot over USB! Specifically, the ROM code exposes an RNDIS class device which will be registered as an Ethernet interface by the host-side rndis_host driver. The ROM code will then broadcast BOOTP requests. A BOOTP server on the network should respond to this and supply the SoC with an IP address and the address of a TFTP server. Finally, the ROM code will download the first stage firmware from this TFTP server. To summarize, here is the expected USB boot procedure for AM335x SoCs:
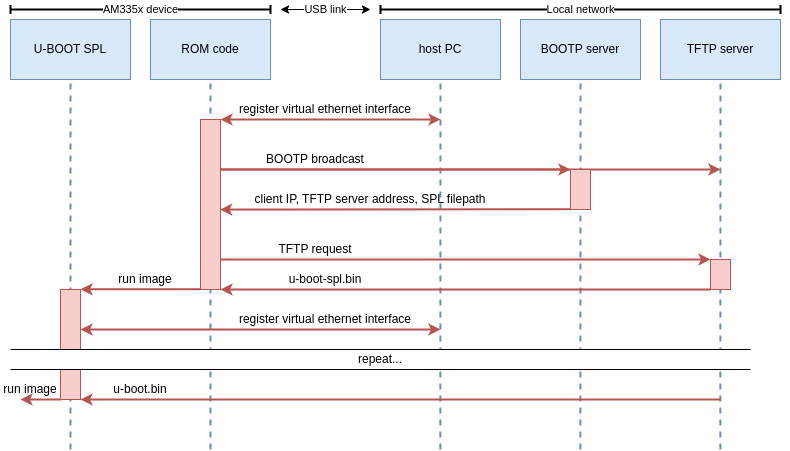
This poses a number of issues. Remember, our goal is to boot the SoC using snagboot, a user-friendly and easily configurable CLI tool. Meaning we can’t expect the user to perform any complicated network configurations to be able to use the tool! So these are the main challenges associated with recovering AM335x SoCs:
- We need a BOOTP and TFTP server to respond to the ROM code. These servers need IP addresses, which means our tool has to obtain IPs every time it runs.
- BOOTP and TFTP servers use ports 67 and 69 which are privileged. However, we don’t want users to have to run snagboot as root.
- The ROM code requires an IP address, which means that snagboot has to supply a valid IP address to it every time it runs the recovery.
- If another BOOTP server is present on the user’s network during recovery, it could try to answer the ROM code, interfering with snagboot’s operation.
Designing a user-friendly recovery process
To circumvent these challenges, we made use of a number of nice Linux features. Firstly, we can see that the common theme in all these issues is interference with the user’s network. We have to work with local routers to get IP addresses, and we have to ensure that other BOOTP servers will not race us to respond to the board. To address this need, we’ve made use of network namespaces, which are a way of partitioning network resources on the system. When a process runs in a separate network namespace, it will not share network interfaces, routing rules, or firewall rules with the rest of the system.
This is very interesting to us, as it means that we can effectively create a sandbox environment where we can interact with the AM335x ROM code without touching the user’s local network! We can set whatever strange routing and firewall rules we want, and they will be automatically destroyed when we delete the namespace! The general sequence for our recovery process is:
- Move the ROM Code’s virtual ethernet interface to a new “snagbootnet” namespace
- Set up firewall rules to link ports 67 and 69 to unprivileged ports 9067 and 9069, which will spare us from running as root.
- Set up routing rules to assign whatever IP’s we want to the ROM interface and the servers generated by snagboot.
- Run snagrecover which will serve a U-Boot SPL image to the ROM Code
- Repeat the same process to serve a U-Boot image to SPL (SPL will use essentially the same boot process as the ROM code)
# These iptable rules will allow snagboot to use unprivileged ports 9067 and 9069 # as proxies for privileged ports 67 and 69 ip netns exec $NETNS_NAME iptables -t nat -A PREROUTING \ -p udp --dport 67 -j DNAT --to-destination :9067 ip netns exec $NETNS_NAME iptables -t nat -A PREROUTING \ -p udp --dport 69 -j DNAT --to-destination :9069 ip netns exec $NETNS_NAME iptables -t nat -A POSTROUTING \ -p udp --sport 9067 -j MASQUERADE --to-ports 67 ip netns exec $NETNS_NAME iptables -t nat -A POSTROUTING \ -p udp --sport 9069 -j MASQUERADE --to-ports 69
The network namespace and network configurations can be done by a wrapper script, that will be executed by the user before running snagboot normally. However, there is another challenging issue with this method. When U-Boot SPL runs, it will expose a new RNDIS interface which will be registered by the host system and be brought up in the default network namespace. This means that we will not be able to access SPL’s virtual ethernet interface from inside our custom network namespace! Thus, we must use one final trick to automatically move SPL’s interface inside our namespace when it is brought up. The namespace setup script will run a polling subprocess in the background. This subprocess will regularly check /sys/class/net for new interfaces matching certain USB addresses, and will automatically move them to our namespace once detected.
poll_interface () {
# check for network interfaces with device nodes matching our ROM code
# and SPL RNDIS gadget addresses
ROMNETFILE=$(grep -l "PRODUCT=$ROMUSB" $(grep -l "DEVTYPE=usb_interface" /sys/class/net/*/device/uevent))
SPLNETFILE=$(grep -l "PRODUCT=$SPLUSB" $(grep -l "DEVTYPE=usb_interface" /sys/class/net/*/device/uevent))
if [ -e "$ROMNETFILE" ]; then
config_interface "$(echo $ROMNETFILE | cut -d '/' -f 5)"
fi
if [ -e "$SPLNETFILE" ]; then
config_interface "$(echo $SPLNETFILE | cut -d '/' -f 5)"
fi
}
You can check out the full setup script by running snagrecover --am335-setup if you are interested.
With this, we have a complete recovery process for AM335! From the user’s points of view, the only big difference with other SoC recoveries is an additional helper script that needs to be run before snagrecover. Designing the AM335x support for Snagboot was a very interesting technical problem, with a solution that illustrated the flexibility offered by Linux systems.
 We are pleased to welcome two additional engineers to our team based in Toulouse, France:
We are pleased to welcome two additional engineers to our team based in Toulouse, France: