Bootlin has been for many years a key contributor to the Buildroot project, a very popular embedded Linux build system. A few years ago, we decided to share our Buildroot expertise by creating a corresponding training course: Embedded Linux development with Buildroot, for which the training materials are freely available, under a Creative Commons license.
We have recently updated this training course up to Buildroot 2019.02, which is the latest “long term support” release of the project. Both the lectures and practical labs have been updated to this Buildroot version.
In addition, the board used in the course has been changed to the BeagleBone Black Wireless, instead of the BeagleBone Black, which is no longer easily available. The practical labs were updated accordingly, and we now use the USB device interface to provide network connectivity between the development PC and the embedded target.
This 3-day Buildroot training course can be delivered on-site at your location, anywhere in the world. See our cost and registration page for more details.
The Netdev 0x13 conference took place last week in Prague, Czech Republic. As we work on a variety of networking topics as part of our Linux kernel contributions, Bootlin engineers Maxime Chevallier and Antoine Ténart went to meet with the Linux networking community and to see a lot of interesting sessions. It’s the third time we enjoy attending the Netdev conference (after Netdev 2.1 and Netdev 2.2) and as always, it was a blast!
The 3-day conference started with a first day of workshops and tutorials. We enjoyed learning how to be the cool kids thanks to the XDP hands-on tutorial where Jesper Brouer and Toke Høiland-Jørgensen cooked us a number of lessons to progressively get to learn how to write and load XDP programs. This was the first trial-run of the tutorial which is meant to be extended and used as a material to go through the XDP basics. The instructions are all available on Github.
We then had the chance to attend the TC workshop where face to face discussions and presentations of the traffic control hot topics being worked on happened. The session caught our attention as the topic is related to current subjects being worked on at Bootlin.
Being used to work on embedded systems, seeing the problems the Network developers face can sometimes come as a surprise. During the TC workshop, Vlad Buslov presented his recent work on removing TC flower’s the dependency to the global rtnl lock, which is an issue when you have a million classification rules to update quickly.
We also went to the hardware offload workshop. The future of the network offload APIs and support in the Linux kernel was discussed, with various topics ranging from ASIC support to switchev advanced use-cases or offloading XDP. This was very interesting to us as we do work on various networking engines providing many offloading facilities to the kernel.
The next two days were a collection of talks presenting the recent advances in the networking subsystem of the Linux kernel, as well as current issues and real-world examples of recent functionalities being leveraged.
As always XDP was brought-up with a presentation of XDP offloading using virtio-net, recent advances in combining XDP and hardware offloading techniques and a feedback from Cloudflare using XDP in their DDOS mitigation in-house solution.
But we also got to see other topics, such as SO_TIMESTAMPING being used for performance analytics. In this talk Soheil Hassas Yeganeh presented how the kernel timestamping facilities can be used to track individual packets withing the networking stack for performance analysis and debugging. This was nice to see as we worked on enabling hardware timestamping in networking engines and PHYs for our clients.
Another hot topic this year was the QUIC protocol, which was presented in details in the very good QUIC tutorial by Jana Iyengar. Since this protocol is fairly new, it was brought-up in several sessions from a lot of interesting angles.
Although QUIC was not the main subject of Alissa Cooper’s keynote on Open Source, the IETF, and You, she explained how QUIC was an example of a protocol that is designed alongside its implementations, having a tight feedback loop between the protocol specifications and its usage in real-life. Alissa shared Jana’s point on how middle-boxes are a problem when designing and deploying new protocols, and explained that an approach to overcome this “ossification” is to encrypt the protocol header themselves and document the invariant parts of the non-encrypted parts.
A consequence of having a flexible protocol is that it is not meant to be implemented in the kernel. However, Maciej Machnikowski and Joshua Hay explained that it is still possible to offload some of the processing to hardware, which sparked interesting discussions with the audience on how to do so.
Conclusion
The Netdev 0x13 conference was well organized and very pleasant to attend. The content was deeply technical and allowed us to stay up-to-date with the latest developments. We also had interesting discussions and came back with lots of ideas to explore.
Thanks for organizing Netdev, we had an amazing time!
It has been over a year since we launched a crowdfunding campaign to fund the development of an upstream Linux kernel driver and userspace support for the Allwinner VPU. The funding campaign was a frank success, with over 400 backers contributing a total of over 30 k€ out of the 17,6 k€ set as the initial goal. This enabled us to work on additional stretch goals, namely support for new Allwinner SoCs and H.265 decoding support.
Initial Development
Work on the Allwinner VPU started back in March 2018, being the main topic of my 6-month internship at our office in Toulouse. Bootlin engineer and long-time Allwinner Linux kernel maintainer Maxime Ripard rapidly joined the effort hands-on, to bring up support for H.264 decoding. Aspects covered by our effort include the kernel driver (cedrus), VAAPI userspace library (libva-v4l2-request) as well as testing tools (v4l2-request-test, libva-dump) and various upstream projects such as VLC and GStreamer.
We worked hard to deliver the campaign’s goals and submitted numerous revisions of the base cedrus driver along the way. By July, we announced the delivery of the campaign’s main goals (although some goals were not fully met, as explained in the associated blog post) and accompanied it with a release (tagged release-2018-07 in our git repositories).
By the end of August, we had added support for MPEG-2, H.264 and H.265 for first-generation Allwinner SoCs (and the H3 in addition), including support for accelerated display of decoded frames in the DRM driver. See our detailed blog post presenting the status at that point. Still, our changes had yet to be included in the Linux kernel.
End of the Year Status
We kept working intermittently on VPU support over the following months and manged to get the Cedrus driver accepted in Linux at the same time as the media request API. We also continued to work on submitting new versions of the series adding H.264 and H.265 support to our driver. Last but not least, we worked on adding support for the H5, A64 and A10 platforms, which were missing from the initial delivery. A dedicated blog post presents the status at the end of 2018.
Recent Developments
In 2019, Bootlin has been continuing the effort to maintain the driver and get the remaining patch series integrated in the mainline Linux kernel. We managed to get the remaining patches for DRM support merged and they will be included in Linux 5.1!
Regarding codecs support, there are still discussions happening around the H.264 and H.265 series which are now at their sixth and third revisions respectively. We are hoping that the situation will settle and that these series will be merged (in staging) as soon as possible.
March 2019 Release
With modifications taking place in the (unstable) kernel interface and userspace being updated accordingly, it became quite hard for users to properly pick the kernel and userspace components that work together. Because of that, we decided to make a new release (tagged release-2019-03 in our git repositories). It packs an updated kernel tree (based on the next media tree with our ongoing patch series applied atop) and matching versions of libva-v4l2-request and v4l2-request-test.
External Contributions
We received a few contributions along the way, such as support for the H6 SoC in the cedrus driver (that should make it to Linux 5.2) and a few minor fixes for the driver. We also received and reviewed improvement to our v4l2-request-test testing tool.
We have been working with Raspberry Pi for quite some time, especially on areas related to the display side. Our work is part of a larger ongoing effort to move away from using the VC4 firmware for display operations and use native Linux drivers instead, which interact with the hardware directly. This transition is a long process, which requires bringing the native drivers to a point where they are efficient and reliable enough to cover most use cases of Raspberry Pi users.
Continuous Integration (CI) plays an important role in that process, since it allows detecting regressions early in the development cycle. This is why we have been tasked with improving testing in IGT GPU Tools, the test suite for the DRM subsystem of the kernel (which handles display). We already presented the work we conducted for testing various pixel formats with IGT on the Raspberry Pi’s VC4 last year. Since then, we have continued the work on IGT and brought it even further.
Improving YUV and Adding Tiled Pixel Formats Support
We continued the work on pixel formats by generalizing support for YUV buffers and reworking the format conversion helpers to support most of the common YUV formats instead of a reduced number of them. This lead to numerous commits that were merged in IGT:
In the meantime, we have also added support for testing specific tiling modes for display buffers. Tiling modes indicate that the pixel data is laid out in a different fashion than the usual line-after-line linear raster order. It provides more efficient data access to the hardware and yields better performance. They are used by the GPU (T tiling) or the VPU (SAND tiling). This required introducing a few changes to IGT as well as adding helpers for converting to the tiling modes, which was done in the following commits:
The display engine hardware used on the Raspberry Pi allows displaying multiple framebuffers on-screen, in addition to the primary one (where the user interface lives). This feature is especially useful to display video streams directly, without having to perform the composition step with the CPU or GPU. The display engine offers features such as colorspace conversion (for converting YUV to RGB) and scaling, which are usually quite intensive tasks. In the Linux kernel’s DRM subsystem, this ability of the display engine hardware is exposed through DRM planes.
Displaying multiple DRM planes
We worked on adding support for testing DRM planes with the Chamelium board, with a fuzzing test that selects randomized attributes for the planes. Our work lead to the introduction of a new test in IGT:
With the Chamelium, there are two major ways of finding out whether the captured display is correct or not:
Comparing the captured frame’s CRC with a CRC calculated from the reference frame;
Comparing the pixels in the captured and reference frames.
While the first method is the fastest one (because the captured frame’s CRC is calculated by the Chamelium board directly), it can only work if the framebuffer and the reference are guaranteed to be pixel-perfect. Since HDMI is a digital interface, this is generally the case. But as soon as scaling or colorspace conversion is involved, the algorithms used by the hardware do not result in the exact same pixels as performing the operation on the reference with the CPU.
Because of this issue, we had to come up with a specific checking method that excludes areas where there are such differences. Since our display pattern resembles a colorful checkerboard with solid-filled areas, most of the differences are only noticeable at the edges of each color block. As a result, we introduced a checking method that excludes the checkerboard edges from the comparison.
Detecting the edges (in blue) of a multi-plane pattern
This method turned out to provide good results and very few incorrect results after some tweaking. It was contributed to IGT with commit:
We also worked on implementing display pipeline underrun detection in the kernel’s VC4 DRM driver. Underruns occur when too much pixel data is provided (e.g. because of too many DRM planes enabled) and the hardware can’t keep up. In addition, a bandwidth filter was also added to reject configurations that would likely lead to an underrun. This lead to a few commits that were already merged upstream:
We prepared tests in IGT to ensure that the underruns are correctly reported, that the bandwidth protection does its job and that both are consistent. This test was submitted for review with patch:
Linux 5.0 was released two weeks ago by Linus Torvalds, and as it is now always the case, Bootlin has contributed a number of patches to this release. For an overview of the new features and improvements brought by Linux 5.0, we as usual recommend to read the LWN articles: merge window summary part 1, merge window summary part 2. The KernelNewbies.org page about this kernel release is also nicely documented.
In terms of contribution to Linux 5.0, according to the LWN statistics, Bootlin is the 12th contributing company by number of commits (261 commits), and 8th contributing company by number of changed lines. Bootlin engineer Maxime Ripard is 11th contributing developer by number of commits, and former Bootlin engineer Boris Brezillon is 12th contributing developer by number of commits, and 8th by number of changed lines. In this release, we are also happy to see numerous contributions from Paul Kocialkoswki who joined Bootlin in November 2018 after his internship working on the Linux kernel support for the Allwinner VPU.
Here are the main highlights of our contributions to Linux 5.0:
After 1.5 years of work, the I3C subsystem was finally merged and visible in drivers/i3c in your favorite kernel tree! We are proud to have pioneered the Linux kernel support for this new MIPI standard, which aims at providing an alternate solution to I2C and SPI, with interesting new features (higher speed, device discovery and enumeration, in-band interrupts, and more). See also our initial blog post about I3C, and our blog post about I3C being upstream.
In the RTC subsystem, Bootlin engineer and RTC kernel maintainer Alexandre Belloni reworked the way nvmem devices are handled, allowing for multiple nvmem devices to be registered for a single RTC as some have both battery-backed RAM and an on-chip EEPROM. devm_rtc_device_register() has been reimplemented to use the new registration path and is now deprecated. Its counterpart, devm_rtc_device_unregister() has been removed.
In the MTD subsystem
Boris Brezillon contributed a number of patches to the support for raw NAND mainly related to refactoring the subsystem. For example, some of the patches make the ->select_chip() of nand_chip a legacy hook, and removes its implementation from a number of drivers. All those patches do not bring any new feature per-se, but are part of a larger effort to clean up and modernize the MTD subsystem.
Boris Brezillon also contributed to the SPI NOR support a mechanism to fixup the information provided in the BFPT table of SPI NOR flashes. This is used to ensure that some Macronix SPI NOR flashes are properly recognized as supporting 4-byte opcodes.
Maxime Ripard contributed a number of improvements to the OV5640 camera sensor driver, especially to remove the hardcoded initialization sequence by a much more flexible initialization code, which allowed to support 60fps and more resolutions.
Maxime Ripard extended the PHY subsystem with two new functions, phy_configure() and phy_validate(), which allow to pass configuration details to PHY drivers. This was then used by Maxime to implement MIPI D-PHY drivers, which need a significant number of configuration parameters. See this commit and this commit for details. MIPI D-PHY are typically used in video display or capture HW pipelines.
As part of our work on RaspberryPi display support, Boris Brezillon contributed a number of fixs to the VC4 display controller driver.
For the support of Microchip MPU (Atmel) platforms, Alexandre Belloni migrated the AT91SAM9260, AT91SAM9261, AT91SAM9263, AT91SAM9RL, AT91SAM9x5, SAMA5D2 and SAMA5D4 platforms to the new clock Device Tree binding that he introduced in Linux 4.20.
For the support of Microchip UNG (formerly Microsemi) platforms, Alexandre Belloni added support for the Jaguar2 platform to the pinctrl driver already used for the Ocelot platform.
For the support of Allwinnner platforms:
Maxime Ripard did a huge amount of Device Tree cleanups and improvements, fixing DTC warnings, but generally making sure those Device Tree files are consistent.
Paul Kocialkowski implemented support for YUV planes in the Allwinner display controller driver. This allows to display a video decoded by the VPU directly into a display controller plane, and let the hardware compose it with other display planes, without CPU intervention.
Paul Kocialkowski enabled the VPU (for hardware-accelerated video decoding) on the Allwinner H5 and A64. This work was part of our crowdfunding campaign around the Allwinner VPU support.
For the support of Marvell platforms
Miquèl Raynal added support for suspend/resume to the SATA support on Armada 3720 (the SoC used for the popular EspressoBin platform), as part of a larger effort of bringing full suspend/resume support on Armada 3720
Miquèl Raynal implemented support for the thermal overheat interrupt on Armada 7K/8K.
Here is the detailed list of commits we contributed to Linux 5.0:
Today, the three Raspberry Pis that we have on our network went down. They were all running Raspbian (Debian for Raspberry Pi) Stretch.
While this issue can be solved, it is serious enough to require to remove the micro-SD card and manually fix the the root filesystem. Therefore, it seems you cannot fix this issue unless you have physical access to your system.
Here are details to attract attention to this issue…
As I started telling you, our systems were down, well almost. Some services were still running, as they were still responding to ping through our VPN. However, SSH access was no longer available:
$ ssh scan
ssh_exchange_identification: Connection closed by remote host
After connecting a serial cable to one of the Pis, and adding init=/bin/sh to the /boot/cmdline.txt file. I found that I couldn’t seem to execute at least some executables. Everything I tried to execute was causing a segmentation fault.
It was time to remove the micro-SD card and look at system logs. Inspecting /var/log/apt/history.log revealed that the raspi-copies-and-fills package was updated yesterday (March. 11, 2019). This allowed me to make a search for issue reports with this package name. Indeed, before having such a lead, I couldn’t find what I was looking for, as there are too many discussions about the use of the Raspberry Pi! So, here’s what I quickly found following this lead:
These posts have all details. All you need to do is take away the micro-SD card, repair the second partition with e2fsck -f /dev/mmcblk0p2 and remove the etc/ld.so.preload file inside this partition.
Note, that at the time of this writing, this issue has already been fixed, so it is safe to upgrade your Pi if it is still up and running, or right after repairing your Raspbian root filesystem.
This incident is very unfortunate, as you need to physically access your board to recover from it. I hope you don’t run updates as frequently as we do (or right after the time when the update was issued), and that your Pis are not impacted, otherwise possibly forcing you to travel or to crawl into difficult to access places to reach your boards.
However, I don’t want blame the community volunteers running Raspbian. They have made a terrific job maintaining this distro which had been flawlessly running for more many years on our systems. This seems as good as what we get from commercial distributions.
I hope that not too many services ran by Raspberry Pis will be disrupted because of this issue. However, that may be yet another way to prove how popular such devices are.
It’s now a tradition: the Buildroot project organizes one of its Buildroot Developers Meeting right after the FOSDEM conference. 2019 was no exception, and the meeting took place from February 4 to February 6, a three days duration, instead of the traditional two days duration from the previous years. Once again, the meeting was sponsored by Google, who provided the meeting location and lunch for all participants. Bootlin participated to the event, by allowing its engineer Thomas Petazzoni to join the meeting.
The meeting was a mix of discussions on various topics and actual hacking, with a focus on reducing the backlog of pending patches. The report synthetizes the most important discussion items:
Some discussions around the download infrastructure took place, related to the re-introduction of the make source-check feature and the issue of tarball reproducibility with version control system download backends
Discussion about introducing Config.in options for all host packages, an idea that we decided to not pursue for the moment.
Discussion about the instrumentation hooks that are used to collect the list of files installed by packages, and how we can achieve this goal in a way that is both efficient and reliable
Discussion on which Qt5 versions to support
Discussion on participating to the Google Summer of Code. We wrote a few topic ideas and applied as an organization for GSoC 2019.
Discussion on how to integrate support for systemd sysusers mechanism
Reading the work on the pending patches, we managed to reduce the backlog from about 300 patches to around 170 patches, which is a very significant achievement.
More specifically, Thomas Petazzoni took advantage of this meeting to:
Finalize his work on the pkg-stats script, to include details about the latest available upstream version of each Buildroot package. To do so, it relies on information provided by the release-monitoring.org website. The information is not yet accurate for all packages, but the accuracy can be improved by contributing to release-monitoring.org. The updated package statistics page now provides those details, which will help ensure Buildroot packages are kept up-to-date.
Review in detail the patch series from Adam Duskett introducing support for GObject Introspection. It is far from a trivial package due to the need to run during the build some small binaries using Qemu. While the series is not merged yet, we have a much better understanding of it, which will help complete the review process.
Do a final review and apply the lengthy patch series reworking the fftw package.
Participate, as a Buildroot co-maintainer, to the pending patches backlog cleanup, by reviewing and/or merging a significant number of patches.
It was once again a very nice and productive meeting. The next meeting will take place as usual around the Embedded Linux Conference Europe, in October, in Lyon (France).
At Bootlin, we owe a lot to the Free Software community, and we’re doing our best to give back as much as we can.
One way of doing that is welcoming community contributors in our public training sessions organized in France. We’ve done that multiple times several years back, and this allowed us to meet very interesting people (who even had very valuable experience and points of view to share with the other course participants), while of course giving them extra knowledge that they can use for further contributions.
Here are the next sessions in which we can offer a free seat:
Don’t hesitate to apply to this free seat. In past editions, we didn’t have so many people applying, and therefore you have a real chance to get selected!
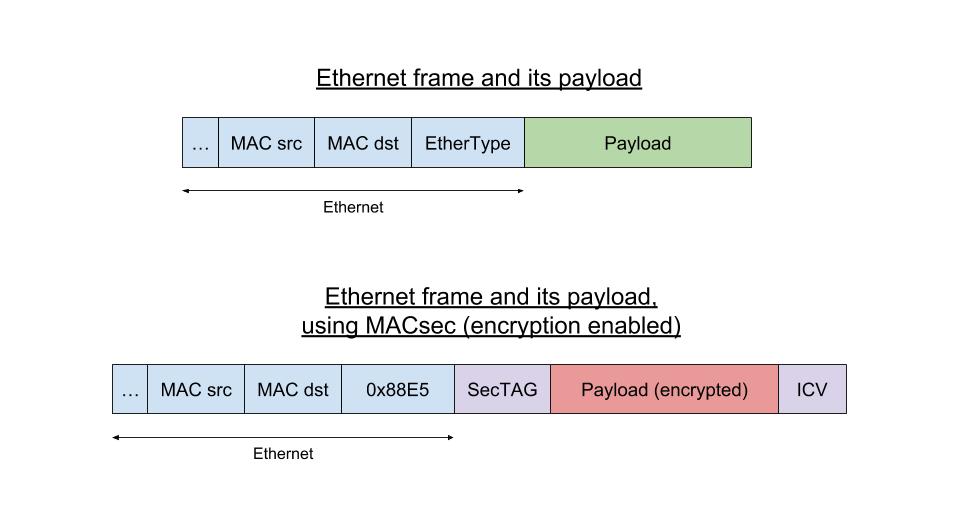
MACsec is an IEEE standard (IEEE 802.1AE) for MAC security, introduced in 2006. It defines a way to establish a protocol independent connection between two hosts with data confidentiality, authenticity and/or integrity, using GCM-AES-128. MACsec operates on the Ethernet layer and as such is a layer 2 protocol, which means it’s designed to secure traffic within a layer 2 network, including DHCP or ARP requests. It does not compete with other security solutions such as IPsec (layer 3) or TLS (layer 4), as all those solutions are used for their own specific use cases.
MACsec uses its own frame format with its own EtherType (a 2-bytes field found in Ethernet frames to indicate what the protocol encapsulated in the payload is). As an example, when encapsulating an IPv4 frame, we would have Ethernet<MACsec<IPv4 instead of Ethernet<IPv4.
The MACsec configuration within a node is represented at the top level by Secure Channels. A secure channel is identified by its SCI (Secure Channel Identifier) and contains parameters such as the encryption, protection and replay protection booleans. A secure channel is either a transmit or a receive one: the receive secure channel configuration on a given host should match the transmit one of another host for MACsec traffic to flow successfully.
Within each secure channel, security associations are described. They are identified by an association number and define the encryption/decryption keys used and the current packet number, which is used for replay protection.
MACsec support in Linux
Linux has a software implementation of MACsec, found at drivers/net/macsec.c, which was introduced by Red Hat engineer Sabrina Dubroca in 2016 and available since Linux 4.5. The support is implemented as full virtual network devices, on per transmit secure channel, attached to a parent network device. The parent interface only sees raw packets, which are in the MACsec case raw Ethernet packets with protected or encrypted content. This design is very similar to other supported protocols in Linux such as VLANs.
MACsec support was also introduced in iproute2, a collection of utilities aiming at configuring various networking parts of the kernel (interfaces management, IP configuration, routes…). The command to use is ip macsec.
If we were to configure a secure channel between two hosts we would first need to create a virtual MACsec interface (representing a transmit secure channel) on both hosts, on top of a physical network interface. Let’s say we use eth0 on both our hosts (Alice and Bob), and we want to encrypt the MACsec traffic:
Alice # ip macsec add link eth0 macsec0 type macsec encrypt on
Bob # ip macsec add link eth0 macsec0 type macsec encrypt on
The next step would be to configure matching receiving secure channel on both hosts:
Alice # ip macsec add macsec0 rx port 1 address <Bob's eth0 MAC>
Bob # ip macsec add macsec0 rx port 1 address <Alice's eth0 MAC>
We would then configure the transmit channels, and for each we would need to generate a key:
Alice # hexdump -n 16 -e '4/4 "%08x" 1 "\n"' /dev/random
d29a43c8cba96a325f6b6a40a214c58c
Alice # ip macsec add macsec0 tx sa 0 pn 1 \
on key d29a43c8cba96a325f6b6a40a214c58c
Bob # hexdump -n 16 -e '4/4 "%08x" 1 "\n"' /dev/random
a1e15a1d91222196fde87b2d75a4fac0
Bob # ip macsec add macsec0 tx sa 0 pn 1 \
on key a1e15a1d91222196fde87b2d75a4fac0
We finally need to configure the receive channels, so that the hosts can authenticate and decrypt packets:
Alice # ip macsec add macsec0 rx port 1 \
address <Bob's MAC> sa 0 pn 1 \
on key 00 a1e15a1d91222196fde87b2d75a4fac0
Bob # ip macsec add macsec0 rx port 1 \
address <Alice's MAC> sa 0 pn 1 \
on key 00 d29a43c8cba96a325f6b6a40a214c58c
Once all of the MACsec configuration is done we would be able to exchange traffic between Alice and Bob, using authenticated and encrypted packets:
Alice # ip link set macsec0 up
Alice # ip addr add 192.168.42.1/24 dev macsec0
Bob # ip link set macsec0 up
Bob # ip addr add 192.168.42.2/24 dev macsec0
What’s coming next: hardware offloading
There are hardware devices featuring a MACsec transformation implementation which can be used to offload the frame generation and encryption / authentication of MACsec frames (for both ingress and egress frames). The benefit of hardware offloading is to discharge the CPU from doing certain operations (in our case MACsec transformations) by doing them in a dedicated hardware engine, which may or may not provide better performance. The idea is essentially to free the CPU from being used by a single application so that the system in its whole runs better.
MACsec offloading devices aren’t currently supported in the Linux kernel and no generic infrastructure is available to delegate MACsec operation to a given hardware device. At Bootlin over the last months we worked on adding such an infrastructure and support for offloading MACsec operations to a first device.
This work was done in two steps. First we needed to extend the current MACsec implementation to propagate commands and configuration to hardware drivers. Our idea was to leverage the current MACsec software implementation to use the exact same commands described above to setup an hardware accelerated MACsec connection, when a Linux networking port supports it. This should allow to have a more maintainable implementation as well.
We then worked on implementing a MACsec specific helper in a networking PHY driver : the Microsemi VSC8584 Ethernet PHY. This PHY has a MACsec engine which can be used to match flows and to perform MACsec transformations and operations. When configured packets can be encrypted and decrypted, protected and validated, without the CPU intervention.
Conclusion
We recently sent a first version of patch series to the Linux network mailing list, which is currently being discussed. This series of patches introduces both the hardware offloading support for MACsec and the ability to offload MACsec operations to a first hardware engine. We hope support for other MACsec engines will come after!
BeagleBoneBlack Wireless board booting through tftp and NFS
Here are details about booting the Beagle Bone Black Wireless board through NFS. I’m writing this here because it doesn’t seem to be documented anywhere else (except in our Linux kernel and driver development course, for which I had to support this feature).
Why
Booting a board on a root filesystem that is a directory on your workstation (development PC) or on a server, shared through the network, is very convenient for development purposes.
For example, you can update kernel modules or programs by recompiling them on your PC, and the target board will immediately “see” the updates. There’s no need to transfer them in some way.
Doing this is quite straightforward on boards that have an Ethernet port, and well documented throughout the Internet (see our instructions). However, things get more complicated with boards that have no such port, such as the Beagle Bone Black Wireless or the Pocket Beagle.
The Beagle Bone Black Wireless board has WiFi support, but booting on NFS directly from the kernel (instead of using an initramfs) is another kind of challenge.
Something easier to use is networking over USB device (also called USB gadget as our operating system is running on the USB device side), which is supported by both Linux and U-Boot.
Note that the below instructions also work on the original Beagle Bone Black, bringing the convenience of not having to use an RJ45 cable. All you need is the USB device cable that you’re using for power supply too.
These instructions should also support the Pocket Beagle board, which is similar, though much simpler.
Preparing U-Boot
This part may just work out of the box if the U-Boot version on your board is recent and was built using the default configuration for your board.
If that’s not the case, you can reflash U-Boot on your board using our instructions.
These instructions have been tested on Ubuntu 18.04, but they should be easy to adapt on other GNU/Linux distributions.
To configure your network interface on the workstation side, we need to know the name of the network interface connected to your board.
However, you won’t be able to see the network interface corresponding to the Ethernet over USB device connection yet, because it’s only active when the board turns it on, from U-Boot or from Linux. When this happens, the network interface name will be enx. Given the value we gave to usbnet_hostaddr, it will therefore be enxf8dc7a000001.
Then, instead of configuring the host IP address from NetWork Manager’s graphical interface, let’s do it through its command line interface, which is so much easier to use:
nmcli con add type ethernet ifname enxf8dc7a000001 ip4 192.168.0.1/24
To download the kernel and device tree blob which are also on your PC, let’s install a TFTP server on it:
sudo apt install tftpd-hpa
You can then test the TFTP connection, which is also a way to test that USB networking works. First, put a small text file in /var/lib/tftpboot.
Then, from U-Boot, do:
tftp 0x81000000 textfile.txt
The tftp command should have downloaded the textfile.txt file from your development workstation into the board’s RAM at location 0x81000000. You can verify that the download was successful by dumping the contents of memory:
md 0x81000000
We are now ready to load and boot a Linux kernel!
Kernel configuration
These instructions were tested with Linux 4.19
Configuring and cross-compiling the Linux kernel for the board is outside the scope of this article, but again, such information is easy to find (such as in our training slides).
Here, we’re just sharing the Linux kernel configuration settings that are needed for networking over USB device. Since they are not supported by the default configuration file for the omap2plus CPU family (for several reasons that were discussed on the Linux kernel mainling list), it took a bit of time to figure out which ones were needed. Here they are:
Add the below options to support networking over USB device:
CONFIG_USB_GADGET=y
CONFIG_USB_MUSB_HDRC=y: Driver for the USB OTG controller
CONFIG_USB_MUSB_GADGET=y: Use the USB OTG controller in device (gadget) mode
CONFIG_USB_MUSB_DSPS=y
Check the dependencies of CONFIG_AM335X_PHY_USB. You need to set CONFIG_NOP_USB_XCEIV=y to be able to set CONFIG_AM335X_PHY_USB=y
Find the ”USB Gadget precomposed configurations” menu and set it to static instead of module so that CONFIG_USB_ETH=y
How did I found out which settings were needed? I had to check the device tree to find the USB device controller. Then, using git grep, I found the driver that was supporting the corresponding compatible string. Then, looking at the Makefile in the driver directory, I found which kernel configuration settings were needed.
When compiling is over, copy the zImage and am335x-boneblack-wireless.dtb files to the TFTP server home directory (/var/lib/tftpboot).
You also need an NFS server on your workstation:
sudo apt install nfs-kernel-server
Then edit the /etc/exports file as root to add the following line, assuming that the IP address of your board will be 192.168.0.100:
Now check the kernel log and make sure an IP address is correctly assigned to your board by Linux. If NFS booting doesn’t work yet, that could be because of NFS server or client issues. If that’s the case, you should find details in the NFS server logs in /var/log/syslog on your PC.
 Bootlin has been for many years a key contributor to the Buildroot project, a very popular embedded Linux build system. A few years ago, we decided to share our Buildroot expertise by creating a corresponding training course: Embedded Linux development with Buildroot, for which the training materials are freely available, under a Creative Commons license.
Bootlin has been for many years a key contributor to the Buildroot project, a very popular embedded Linux build system. A few years ago, we decided to share our Buildroot expertise by creating a corresponding training course: Embedded Linux development with Buildroot, for which the training materials are freely available, under a Creative Commons license. In addition, the board used in the course has been changed to the BeagleBone Black Wireless, instead of the BeagleBone Black, which is no longer easily available. The practical labs were updated accordingly, and we now use the USB device interface to provide network connectivity between the development PC and the embedded target.
In addition, the board used in the course has been changed to the BeagleBone Black Wireless, instead of the BeagleBone Black, which is no longer easily available. The practical labs were updated accordingly, and we now use the USB device interface to provide network connectivity between the development PC and the embedded target.




 It’s now a tradition: the
It’s now a tradition: the 
 At Bootlin, we owe a lot to the Free Software community, and we’re doing our best to give back
At Bootlin, we owe a lot to the Free Software community, and we’re doing our best to give back