Videos from the Embedded Linux Conference Europe, Cambridge, UK, October 2010
Just a few weeks before the next edition of the Embedded Linux Conference in San Francisco, here are the videos from the previous edition in Europe a few months ago.
These videos took more time to process than expected, because of intense months on our side, but also because of the switch to the VP8 video codec. VP8 is the new Open Source and royalty free video codec, and is a successor to the codec that Theora was derived from. Unlike Theora which is now lagging behind, it is a very close competitor to H264, both in terms of quality and video size.
The switch to VP8 allowed us to release the videos in their original full HD resolution (we now have three full HD camcorders to shoot conference videos), with video files of about the same size.
You will probably need a recent GNU/Linux distribution (such as Ubuntu 10.10) to watch these videos. As this codec released by Google is taking off quickly, you should also find solutions to watch videos on Windows and MacOS X. Don’t hesitate to post comments here about your experience playing these files. You can even watch them on the Panda board, which can decode VP8 with its hardware video decoder.
As usual, these videos are released under the terms of the Creative Commons Attribution – ShareAlike Licence version 3.0.
As often in conferences, the videos were unfortunately shot is tough lighting conditions. The organizers usually turn off the lights to make it easier for the audience to read the screen. The consequence is a high contrast between the speaker and the screen, causing the speaker to appear very dark when we film her or him together with the screen. In a number of videos, we tried to solve this by using a beach mode provided by our camcorders. While the speaker now looks great, this unfortunately blurred the screen, causing more inconvenience than benefits. We gave up this mode in the last videos and will shoot ELC 2011 is the standard way, even if the speaker looks dark again. At least, with full HD videos, you will be able to read the slides directly on the screen.
The videos from the 2010 GStreamer conference will also be available in the next days, and to help you produce your own videos, we will release our new video processing scripts soon too.
Ruud Derwig
Welcome speech
Video (15 minutes):
full HD (228M), 450×800 (71M)
Wolfram Sang
Pengutronix
Developer’s Diary: Supporting Maintainers
Slides
Video (46 minutes):
full HD (888M)
Rekha Kumar and Nipuna Gunasekera
Texas Instruments
Panda board demonstration
Video (14 minutes):
full HD (373M), 450×800 (85M)
Robert Schuster
OpenJDK
OpenJDK for Embedded Linux Devices
Slides
Video (39 minutes):
full HD (947M), 450×800 (225M)
Philippe Robin
Linaro
Facilitating Open Source Development and Collaboration
Slides
Video (46 minutes):
full HD (548M), 450×800 (160M)
Tim Bird
Sony
Android System Programming – Tips and Tricks
Slides
Video (40 minutes):
full HD (471M), 450×800 (142M)
Mischa Jonker and Ruud Derwig
Synopsys
Portability is for People Who Cannot Write New Programs – GNU/Linux/OS on ARC
Slides
Video (34 minutes):
full HD (517M), 450×800 (148M)
Leif Lindholm
ARM
Software Considerations When Using High-Performance Memory Systems
Slides
Video (46 minutes):
full HD (511M), 450×800 (153M)
Ravi Sankar Guntur
Samsung
A Simple Method to Detect Memory Leaks and Buffer Overruns
Slides
Video (17 minutes):
full HD (171M), 450×800 (55M)
Will Newton
Imagination Technologies
Exploiting On-chip Memories in Embedded Linux Applications
Slides
Video (20 minutes):
full HD (255M), 450×800 (68M)
Andrey Fedotov
AFSoft
Linux Application in Safety-Critical Environment: A Real-Life Example
Video (39 minutes):
full HD (304M), 450×800 (111M)
Anna Dushistova
Mentor Graphics
Eclipse and Embedded Linux Developers: What It Can and What It Cannot Do For You
Slides
Video (31 minutes):
full HD (338M), 450×800 (112M)
Yoshitake Kobayashi
Toshiba
Linux Kernel Acceleration for Long-term Testing
Slides
Video (30 minutes):
full HD (249M), 450×800 (89M)
Ralf Baechle
Wind River
Embedded Linux – The State of the Nation
Video (40 minutes):
full HD (375M), 450×800 (128M)
Jim Zemlin
Linux Foundation
The Linux Foundation and CELF
Video (21 minutes):
full HD (282M), 450×800 (71M)
Andrew Murray
MPC Data
The Right Approach to Minimal Boot Times
Slides
Video (41 minutes):
full HD (472M), 450×800 (149M)
Robert Schwebel and Sascha Hauer
Pengutronix
Barebox: Booting Linux Fast and Fancy
Slides
Video (45 minutes):
full HD (779M), 450×800 (192M)
Kevin Hilman
Deep Root Systems
Runtime Power Management
Slides
Video (45 minutes):
full HD (780M), 450×800 (195M)
Michael Opdenacker
Bootlin
Flash Filesystem Benchmarks
Slides
Video (47 minutes):
full HD (937M), 450×800 (229M)
Ari Rauch
Texas Instruments
The Dynamic Role of Open Linux Architectures in Today’s Mobile Landscape
Slides
Video (34 minutes):
full HD (789M), 450×800 (203M)
Benjamin Gaignard
ST-Ericsson
Android and GStreamer
Slides
Video (42 minutes):
full HD (432M), 450×800 (133M)
Hans Verkuil
Tandberg
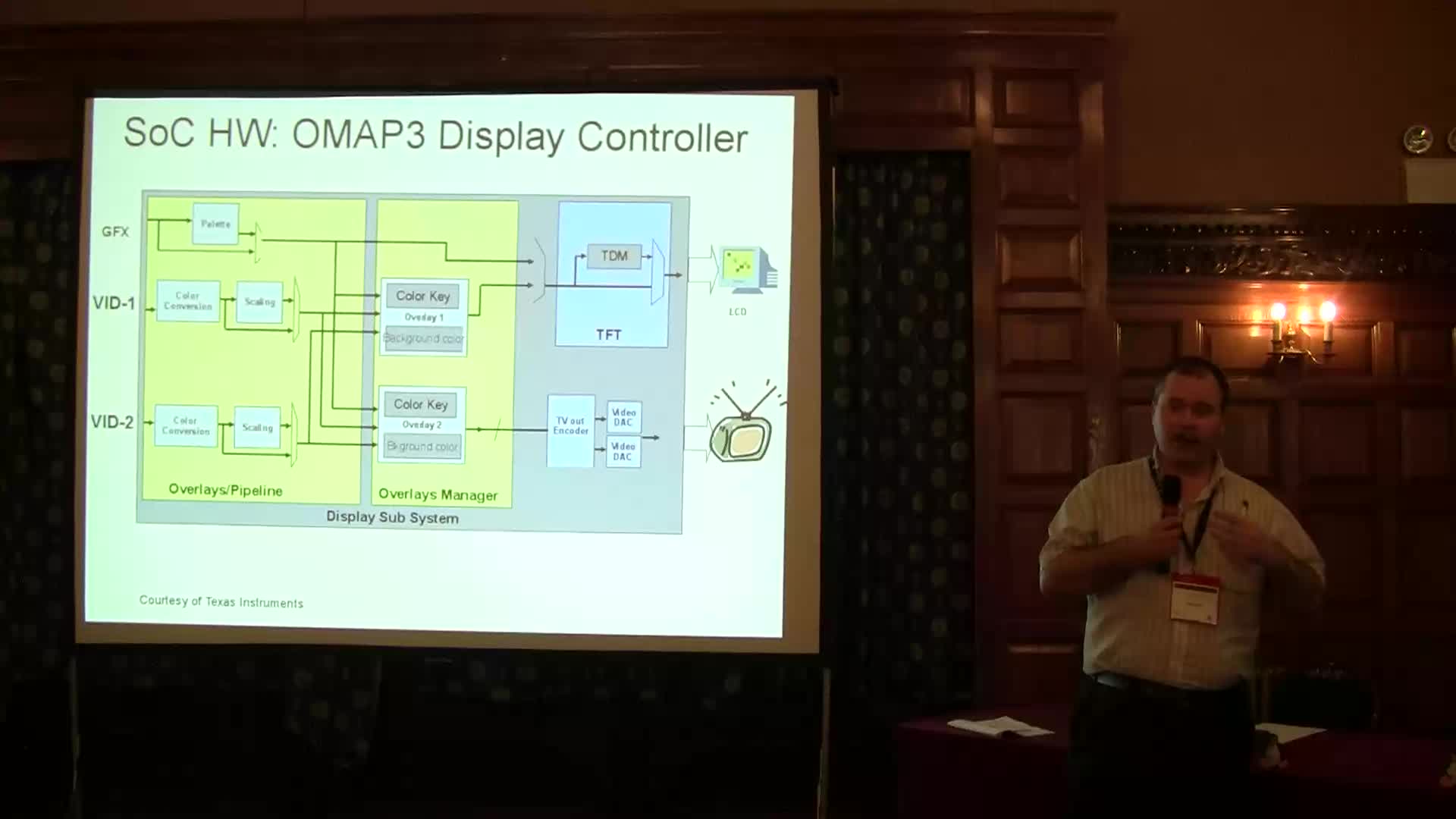
Supporting SoC Video Subsystems in Video4linux
Slides
Video (45 minutes):
full HD (424M), 450×800 (139M)
Benjamin Zores
Alcatel-Lucent
State of Multimedia in 2010’s Embedded Linux Devices
Slides
Video (45 minutes):
full HD (784M), 450×800 (219M)
Iago Toral Quiroga
Igalia/Grilo
Grilo: Integrating Multimedia Content in Applications
Slides
Video (32 minutes):
full HD (515M), 450×800 (149M)
Jean-Paul Saman
M2X BV
Porting VLC to TI DaVinci
Slides
Video (46 minutes):
full HD (516M), 450×800 (167M)
Stefan Kost
Nokia
Meego Multimedia
Slides
Video (37 minutes):
full HD (316M), 450×800 (105M)
Vitaly Wool
Porting Legacy Code to Linux Userspace Driver Framework
Video (26 minutes):
full HD (400M), 450×800 (108M)
Martin Michlmayr
Debian
Adapting Debian Installer to NAS and Other Consumer Devices
Slides
Video (21 minutes):
full HD (196M), 450×800 (62M)
Frank Scholz
Android and Its Impact On Home Entertainment and Home Automation
Video (28 minutes):
full HD (347M), 450×800 (101M)
Wookey
Yaffs
Yaffs updates
Slides
Video (27 minutes):
full HD (312M), 450×800 (95M)
Yann E. Morin
Crosstool-ng
Crosstool-NG, A Cross-Toolchain Generator
Slides
Video (41 minutes):
full HD (1.1G), 450×800 (185M)
Armijn Hemel
Loohuis Consulting
Introducing the Binary Analysis Tool
Slides
Video (47 minutes):
full HD (507M), 450×800 (155M)
Kees-Jan Dijkzeul
Sioux Embedded Systems
A Gentle Introduction to Autotools
Slides
Video (41 minutes):
full HD (371M), 450×800 (124M)
Klaas Van Gend
Montavista
Deflating the Virtualization Hype in 3 Simple Steps
Slides
Video (38 minutes):
full HD (507M), 450×800 (131M)
Peter Korsgaard
Buildroot
Do More With Less – On Driver-less Interfacing with Embedded Devices
Slides
Video (48 minutes):
full HD (529M), 450×800 (173M)
Ray Kinsella
Intel
Xen in Embedded Systems
Slides
Video (34 minutes):
full HD (380M), 450×800 (135M)
Arnout Vandecappelle
Mind
Practical Testing of Open Source Embedded Systems
Slides
Video (51 minutes):
full HD (364M), 450×800 (160M)
Carmelo Amoroso and Rosario Contarino
STMicroelectronics
Lightweight Prelinker for Kernel Modules
Slides
Video (45 minutes):
full HD (302M), 450×800 (129M)
Frank Rowand
Sony
Identifying Embedded Real-Time Latency Issues: I-Cache and Locks
Slides
Video (43 minutes):
full HD (272M), 450×800 (120M)
David Anders
Texas Instruments
Board Bringup: Methods and Utilities
Slides
Video (34 minutes):
full HD (248M), 450×800 (99M)
John Ogness
Linutronix
IPL+UBI: Flexible and Reliable with Linux as the Bootloader
Slides
Video (27 minutes):
full HD (232M), 450×800 (89M)
Vitaly Wool
WLAN Chips in Embedded Linux Systems
Video (23 minutes):
full HD (264M), 450×800 (82M)
Grant Likely
Secret Lab Technologies
ARM Flattened Device Tree Status Report
Slides
Video (40 minutes):
full HD (542M), 450×800 (173M)
Koen Kooi
OpenEmbedded
The State of OpenEmbedded and Tooling to Make Life Easier
Slides
Video (44 minutes):
full HD (308M), 450×800 (122M)
Harald Welte
OpenBSC
Running your own GSM+GPRS network using OpenBSC, OsmoSGSN and OpenGGSN
Slides
Video (49 minutes):
full HD (402M), 450×800 (163M)
Arun Raghavan
Collabora
PulseAudio In The Embedded World
Slides
Video (30 minutes):
full HD (204M), 450×800 (88M)
Jake Edge
LWN.net
Understanding Threat Models for Embedded Devices
Slides
Video (29 minutes):
full HD (186M), 450×800 (80M)
Gustavo F. Padovan
Profusion
The Linux Bluetooth Stack
Slides
Video (30 minutes):
full HD (213M), 450×800 (87M)
Klaas van Gend
Closing session
Video (62 minutes):
full HD (1.2G), 450×800 (285M)
Chris Simmonds
2net
The Embedded Linux Quick Start Guide – Part 1
Slides
Video (52 minutes):
full HD (397M)
Chris Simmonds
2net
The Embedded Linux Quick Start Guide – Part 2
Slides
Video (79 minutes):
full HD (660M)
Chris Simmonds
2net
The Embedded Linux Quick Start Guide – Part 3
Slides
Video (67 minutes):
full HD (501M)
Chris Simmonds
2net
What else can you do with Android? – Part 1
Slides
Video (49 minutes):
full HD (432M), 450×800 (144M)
Chris Simmonds
2net
What else can you do with Android? – Part 2
Slides
Video (31 minutes):
full HD (293M), 450×800 (94M)
Chris Simmonds
2net
What else can you do with Android? – Part 3
Slides
Video (59 minutes):
full HD (545M), 450×800 (180M)
Here are also videos of the Embedded Linux and Android tutorials by Chris Simmonds.





































































 The success of the BeagleBoard platform, a low-cost development platform, that has greatly contributed to the success of Texas Instruments OMAP3 processor in the embedded Linux industry, seems to have inspired another processor manufacturer: ST Ericsson. They have recently unveiled
The success of the BeagleBoard platform, a low-cost development platform, that has greatly contributed to the success of Texas Instruments OMAP3 processor in the embedded Linux industry, seems to have inspired another processor manufacturer: ST Ericsson. They have recently unveiled 

