This year’s edition of the Linux Media Summit happened a month ago, in Edinburgh, right after the Embedded Linux Conference. Since we were already at the ELCE, and that we’ve been more and more involved in the media community thanks to our work on the Allwinner CSI driver and more importantly the Cedrus driver, it was natural for us to attend.
The media summit is usually a meeting to discuss the hot topics, so the whole day was a mix and match of various status updates and discussions on the future needs and developments around the Video4Linux2 framework.
Most of the discussion was about how to improve the contributor’s experience and improve the maintenance. The DRM subsystem was used as an example, since the number of patches are in the same order of magnitude, and a number of v4l2 contributors are also contributing to DRM drivers. Part of the improvement of both the maintenance and contribution experience will also come through some CI work, so there was a lot of discussions on how to improve the already existing tools (such as v4l2-compliance) but also how to setup some automatic tooling to run those tests as early as possible.
A good part of the day was also spent on dealing with the current developments, such as the Request API we’ve used in the Cedrus driver, and how to integrate that API into popular multimedia frameworks like gstreamer or ffmpeg. It looks like our libva implementation was well received, so it will probably be made standard and hosted on linuxtv.org in the near future. Other developments discussed were fault tolerant v4l2, in order to deal with video pipelines where one or several components might not work anymore, and storing the v4l2 controls state in a persistent way.
It was overall a very productive day, and it’s always nice to meet people you interact with over mailing list and IRC on a regular basis. If you want more information, you can read the extensive report.
This year’s edition of the X.org Developpers Conference (XDC) happened two weeks ago in A Coruña, Spain. While its name suggests that it might be focused solely on the X.org display server, this conference is actually targeted at the whole Linux graphics stack, including alternative stacks like Android’s or Wayland servers. Following our involvment in the Linux DRM subsystem, and to deepen our understanding and involvement in the graphics stack, Bootlin sent one engineer, Maxime Ripard, maintainer of the sun4i DRM driver.
There’s been a lot of interesting talks during those three days, as you can see in the conference schedule, but we especially liked a few of those:
Jens Owens, Pierre-Loup Griffais – Open Source Driver Development Funding Hooking up the Money Hose – Slides
The opening talk was made by Jens Owens, from Google, and Pierre-Loup Griffais, from Valve. They provided some interesting feedback and insights from two companies with a quite central position in the gaming industry. They also advocated for open source drivers, and the way they were actually helping the game developpers.
Haneen Mohamed and Rodrigo Siqueira were on stage to talk about their work as part of the Google Summer of Code and Outreachy programs to work on a Virtual KMS driver. This driver is still in its early stage, but got merged and while basic at the moment, holds a lot of promises to use it as a KMS backend for testing the KMS API.
Jerome Glisse – getting rid of get_user_page() in favor of HMM – Slides
Jerome Glisse, from Red Hat, came to describe his current work on the memory management subsystem of the Linux kernel. He’s working on dealing with the constraints that the systems using GPUs to offload computations have when it comes to allocating memory in the most efficient way.
Overall, this was a great description about the get_user_page interface pitfalls when used in that context, and from the work that he has been doing for the past years to overcome them.
In that talk, Lyude Paul and Alyssa Rosenzweig were showing the work they did on Panfrost, the reverse-engineering effort around the Mali-T GPUs from ARM (which was then expanded to the Mali-G GPUs). They discussed the result of their findings, explained the architecture of the GPU and then talked about the current state of their work. The final part of the talk was a quick demo of their work on a Rockchip SoC. It provided a great overview of the current state of the driver, and there’s a lot of hope for an open-source driver for that GPU that is quite widely used on ARM.
Elie Tournier – What’s new in the virtual world? – Slides
Elie Tournier, from Collabora, gave a talk about his work and the current state of virgl, which is a virtual 3D GPU meant to be used within qemu virtual machines, while remaining independant of the host GPU. While we were aware of the existence of that driver for quite some time, this talk provided a great overview of the features that are provided by virgl, and what you can and cannot do with it.
Conclusion
After XDC in 2016 in Helsinki, this was our second time attending that conference. Just like the first time, we really enjoyed the single track format where you can meet all the attendees and have side discussions pretty easily. Once again, the talks were great, and lead us to think about interesting developments we could do on our various projects.
Back in September, we announced the availability of Mali userspace blobs that provide OpenGL acceleration on Allwinner platforms using the mainline Linux kernel. Back then, only the r6p2 version of the Mali blobs were available, with only the x11 and fbdev backends, and only for ARM 32 bits. Following the announcement we made last September, we kept talking with Allwinner to release more binaries and increase the usefulness of them. Two major categories were missing in order to complete the previous batch of binaries Allwinner allowed us to distribute: Wayland and arm64 flavours.
After some discussions, Allwinner provided to us this week additional Mali blobs, covering Wayland support, ARM64, and also newer versions for some of them. Overall, we now provide:
r6p2 version, ARM 32 bits, X11
r6p2 version, ARM 32 bits, fbdev
r6p2 version, ARM 32 bits, Wayland (new)
r6p2 version, ARM 64 bits, X11 (new)
r6p2 version, ARM 64 bits, fbdev (new)
r6p2 version, ARM 64 bits, Wayland (new)
r8p1 version, ARM 32 bits, fbdev (new)
r8p1 version, ARM 64 bits, fbdev (new)
We pushed everything to our github repo, enjoy! See our previous blog post for instructions on how to use those blobs.
Those binary blobs are useful because they allow today to have a fully working OpenGL acceleration on Allwinner platforms: we recently ran a Qt5 application doing OpenGL rendering 24/7 on an Allwinner A33 platform for 1.5 month uninterrupted, as a stability test. Of course, long term, we are following the progress of the Lima project, which will provide a completely free and open-source solution to provide OpenGL acceleration on Allwinner platforms.
As part of our ongoing work with the RaspberryPi Foundation, we’ve been working on a number of display-related topics recently. Besides the work done by my colleague Boris Brezillon on improving the kernel side support for a number of features (such as the GPU performance counters support, memory management improvements, etc.), I’ve been working on improving the CI infrastructure for display driver testing.
Indeed, the current workflow is not automated at all and doesn’t allow to detect breakages in the display driver. We thus needed to improve that. To do so, we’ve relied on a board developed by Google as part of the ongoing CI-effort on ChromeOS that is called the Chamelium. The Chamelium is based on an ARM board powered by an Altera SoC+FPGA platform that Google extended with an extension board with video connectivity: VGA, HDMI and DisplayPort. They then developed a firmware for the FPGA to allow the board to emulate a screen.
A RaspberryPi and the Chamelium
Using this, you can simulate improper EDIDs, simulate hotplug events, HDCP screens, etc. and see how the device under test reacts to that. One of the interesting things you can do with it is to dump a CRC of the frame received on the display link, or a raw capture of a given number of frames. The usefulness of such a feature is obvious for a CI effort: you connect the device to test over HDMI, VGA or DP to the Chamelium, and then you can setup a test pattern on the device you want to test, capture the frame received on the other end, and compare the two frames. In an ideal scenario, the two are identical, and if your driver has a regression, you’ll notice as the two frames would no longer be identical.
The intel-gpu-tools suite (also called i-g-t), even though historically named with a not-so-generic name, is a standard test suite for the DRM subsystem in Linux. Last summer, the support for the Chamelium has been introduced for exactly this setup, where intel-gpu-tools would setup a test pattern, ask the Chamelium for a CRC of the frames it received and do the comparison.
This was working fine, and after a quick test on the RaspberryPi, it turned out to work on non-Intel hardware out of the box. However, the test was actually quite simple: while it was testing all the resolutions exposed, it was only testing a single pixel format, and we wanted to do more in order to catch regressions in less common formats, and ideally the RaspberryPi proprietary formats as well.
When it comes to pixel formats, there are two main families involved:
the RGB formats, sometimes prefixed with an A (for alpha, the opacity) or X (for padding), and the YCbCr family (also called abusively YUV). The former will have different values for each primary color, encoded on a number of bits following the RGB prefix. XRGB1555 for example will be a 16 bits format (1 + 5 + 5 + 5), with 1 bit of padding, and 5 bits for red, green and blue in that order.
the YCbCr formats, based on the property of the human eye that it perceives better the changes in luminosity than in color and will thus store the luminance (Y) and chrominance (Cb and Cr) in separate fields, with possibly a different number of bits. While RGB is usually preferred by computer graphics, video is very fond of the YCbCr formats since you can compress the Cb and Cr fields, resulting in a denser pixel format, without degrading the image quality too much.
The format initially supported by intel-gpu-tools was the XRGB8888 (8 bits of padding, 8 bits for red, green and blue, in that order). The RaspberryPi supports the RGB formats XRGB8888, ARGB8888, ABGR8888, XBGR8888, RGB565, BGR565, ARGB1555, XRGB1555, RGB888, BGR888.
Like we said, i-g-t was on the contrary using only an XRGB8888 format for the test pattern. This unfortunately was based on a few assumptions, the first one being that the test pattern would be generated with Cairo. However, Cairo supports a very limited range of formats. On the formats supported on the RaspberryPi, Cairo only supported ARGB8888, XRGB8888 and RGB565. This was obviously not enough, but we didn’t really want to extend Cairo since our goal was to be able to run the test suite on as many devices as possible. One option would have been to update the version of Cairo in use to support a larger number of formats, but that was not considered to be the most appropriate solution. We thus evaluated our options, and it turned out pixman supports most of the RGB formats, and it was already a dependency of intel-gpu-tools.
So in a patch series that we submitted recently to the intel-gpu-tools project, we:
create an API to allow the core i-g-t functions that handle the buffers to let us simply map the underlying DRM buffer in order to access it, without having to use Cairo and its limited pixel format support
rework the code a bit to be able to use Cairo when relevant, and then fallback to Pixman if the format isn’t supported. Pixman list of formats supported isn’t ideal either, especially in the YCbCr family, but we focused on RGB first. In order to allow for additional fallbacks, we hid it behind an API so that it’s transparent to the users
create a custom pattern solely for the Chamelium test, which was needed to deal with the difference of sampling size for each color component
glue those functions into the Chamelium test suite and add one sub-test for each format, so that we can detect both regressions in handling the format itself, but also regressions in the list of formats exposed
All this work has then be submitted to the intel-gpu-tools mailing list for review, and while the development was done on a RaspberryPi, it should benefit the whole community.
As most people know, getting GPU-based 3D acceleration to work on ARM platforms has always been difficult, due to the closed nature of the support for such GPUs. Most vendors provide closed-source binary-only OpenGL implementations in the form of binary blobs, whose quality depend on the vendor.
This situation is getting better and better through vendor-funded initiatives like for the Broadcom VC4 and VC5, or through reverse engineering projects like Nouveau on Tegra SoCs, Etnaviv on Vivante GPUs, Freedreno on Qualcomm’s. However there are still GPUs where you do not have the option to use a free software stack: PowerVR from Imagination Technologies and Mali from ARM (even though there is some progress on the reverse engineering effort).
Allwinner SoCs are using either a Mali GPU from ARM or a PowerVR from Imagination Technologies, and therefore, support for OpenGL on those platforms using a mainline Linux kernel has always been a problem. This is also further complicated by the fact that Allwinner is mostly interested in Android, which uses a different C library that avoids its use in traditional glibc-based systems (or through the use of libhybris).
However, we are happy to announce that Allwinner gave us clearance to publish the userspace binary blobs that allows to get OpenGL supported on Allwinner platforms that use a Mali GPU from ARM, using a recent mainline Linux kernel. Of course, those are closed source binary blobs and not a nice fully open-source solution, but it nonetheless allows everyone to have OpenGL support working, while taking advantage of all the benefits of a recent mainline Linux kernel. We have successfully used those binary blobs on customer projects involving the Allwinner A33 SoCs, and they should work on all Allwinner SoCs using the Mali GPU.
In order to get GPU support to work on your Allwinner platform, you will need:
The kernel-side driver, available on Maxime Ripard’s Github repository. This is essentially the Mali kernel-side driver from ARM, plus a number of build and bug fixes to make it work with recent mainline Linux kernels.
The Device Tree description of the GPU. We introduced Device Tree bindings for Mali GPUs in the mainline kernel a while ago, so that Device Trees can describe such GPUs. Such description has been added for the Allwinner A23 and A33 SoCs as part of this commit.
The userspace blob, which is available on Bootlin GitHub repository. It currently provides the r6p2 version of the driver, with support for both fbdev and X11 systems. Hopefully, we’ll gain access to newer versions in the future, with additional features (such as GBM support).
If you want to use it in your system, the first step is to have the GPU definition in your device tree if it’s not already there. Then, you need to compile the kernel module:
It should install the mali.ko Linux kernel module into the target filesystem.
Now, you can copy the OpenGL userspace blobs that match your setup, most likely the fbdev or X11-dma-buf variant. For example, for fbdev:
git clone https://github.com/bootlin/mali-blobs.git
cd mali-blobs
cp -a r6p2/fbdev/lib/lib_fb_dev/lib* $TARGET_DIR/usr/lib
You should be all set. Of course, you will have to link your OpenGL applications or libraries against those user-space blobs. You can check that everything works using OpenGL test programs such as es2_gears for example.
We have been working for almost two years now on the C.H.I.P platform from Nextthing Co.. One of the characteristics of this platform is that it provides an expansion headers, which allows to connect expansion boards also called DIPs in the CHIP community.
In a manner similar to what is done for the BeagleBone capes, it quickly became clear that we should be using Device Tree overlays to describe the hardware available on those expansion boards. Thanks to the feedback from the Beagleboard community (especially David Anders, Pantelis Antoniou and Matt Porter), we designed a very nice mechanism for run-time detection of the DIPs connected to the platform, based on an EEPROM available in each DIP and connected through the 1-wire bus. This EEPROM allows the system running on the CHIP to detect which DIPs are connected to the system at boot time. Our engineer Antoine Ténart worked on a prototype Linux driver to detect the connected DIPs and load the associated Device Tree overlay. Antoine’s work was even presented at the Embedded Linux Conference, in April 2016: one can see the slides and video of Antoine’s talk.
However, it turned out that this Linux driver had a few limitations. Because the driver relies on Device Tree overlays stored as files in the root filesystem, such overlays can only be loaded fairly late in the boot process. This wasn’t working very well with storage devices or for DRM that doesn’t allow hotplug of some components. Therefore, this solution wasn’t working well for the display-related DIPs provided for the CHIP: the VGA and HDMI DIP.
The answer to that was to apply those Device Tree overlays earlier, in the bootloader, so that Linux wouldn’t have to deal with them. Since we’re using U-Boot on the CHIP, we made a first implementation that we submitted back in April. The review process took its place, it was eventually merged and appeared in U-Boot 2016.09.
However, the U-Boot community also requested that the changes should also be merged in the upstream libfdt, which is hosted as part of dtc, the device tree compiler.
Following this suggestion, Bootlin engineer Maxime Ripard has been working on merging those changes in the upstream libfdt. He sent a number of iterations, which received very good feedback from dtc maintainer David Gibson. And it finally came to a conclusion early October, when David merged the seventh iteration of those patches in the dtc repository. It should therefore hopefully be part of the next dtc/libfdt release.
List of relevant commits in the Device Tree compiler:
Since the libfdt is used by a number of other projects (like Barebox, or even Linux itself), all of them will gain the ability to apply device tree overlays when they will upgrade their version. People from the BeagleBone and the Raspberry Pi communities have already expressed interest in using this work, so hopefully, this will turn into something that will be available on all the major ARM platforms.
The X.org Foundation hosts every year around september the X.org Developer Conference, which, unlike its name states, is not limited to X.org developers, but gathers all the Linux graphics stack developers, including X.org, Mesa, wayland, and other graphics stacks like ChromeOS, Android or Tizen.
This year’s edition was held last week in the University of Haaga-Helia, in Helsinki. At Bootlin, we’ve had more and more developments on the graphic stack recently through the work we do on Atmel and NextThing Co’s C.H.I.P., so it made sense to attend.
There’s been a lot of very interesting talks during those three days, as can be seen in the conference schedule, but we especially liked a few of those:
The opening talk was made by two Google engineers from the ChromeOS team, Sean Paul and Zach Reizner. They talked about the work they did on the drm_hwcomposer they wrote for the Pixel C, on Android.
The hwcomposer is one of the HAL in Android that interfaces between Surface Flinger, the display manager, and the underlying display driver. It aims at providing hardware composition features, so that Android can leverage the capacities of the display engine to perform compositions (through planes and sprites), without having to use the CPU or the GPU to do this work.
The drm_hwcomposer started out as yet another hwcomposer library implementation for the tegra-drm driver in Linux. While they implemented it, it turned into some generic enough implementation that should be useful for all the DRM drivers out there, and they even introduced some particularly nice features, to split the final screen content into several planes based on the actual displayed content rather than on windows like it’s usually done.
Their work also helped to point out a few flaws in the hwcomposer API, that will eventually be fixed in a new revision of that API.
The next talk was once again from a ChromeOS engineer, David Reveman, who came to show his work on ARC++, the component in ChromeOS that allows to run Android applications. He was obviously mostly talking about the display side.
In order to achieve that, he had to implement an hwcomposer that would just act as a proxy between SurfaceFlinger and Wayland that is used on the ChromeOS side. The GL rendering is still direct though, and each Android application will talk directly to the GPU, as usual. Only the composition will be forwarded to the ChromeOS side.
In order to minimize that composition process, whenever possible, ARC++ tries to back each application with an overlay so that the composition would happen directly in hardware.
This also led to some interesting challenges, especially since some of the assumptions of both systems are in contradiction. For example, any application can be resized in ChromeOS, while it’s not really a thing in Android where all the applications run full screen.
The next talk we found interesting was Andy Ritger from nVidia explaining how the HDR displays were supposed to be handled in Linux.
He first started by explaining what HDR is exactly. While the HDR is just about having a wider range of luminance than on a regular display, you often also get a wider gamut with HDR capable displays. This means that on those screens you can display a wider range of colors, and with a better range and precision in their intensity. And
while the applications have been able to generate HDR content for more than 10 years, the rest of the display stack wasn’t really ready, meaning that you had convert the HDR colors to colors that your monitor was able to display, using a technique called tone mapping.
He then explained than the standard, non-HDR colorspace, sRGB, is not a linear colorspace. This means than by doubling the encoded luminance of a color, you will not get a color twice brighter on your display. This was meant this way because the human eye is much more sensitive to the various shades of colors when they are dark than when they are bright. Which essentially means that the darker the color is, the more precision you want to get.
However, the luminance “resolution” on the HDR display is so good that you actually don’t need that anymore, and you can have a linear colorspace, which is in our case SCRGB.
But drawing blindly in all your applications in SCRGB is obviously not a good solution either. You have to make sure that your screen supports it (which is exposed through its EDIDs), but also that you actually tell your screeen to switch to it (through the infoframes). And that requires some support in the kernel drivers.
This talk by Jason Ekstrand was some kind of a war story of the bring up Intel did of a Vulkan implementation on their GPU.
He first started by saying that it was actually a not so long project, especially when you consider that they wrote it from scratch, since it took roughly 3 full-time engineers 8 months to come up with a fully compliant and open source stack.
He then explained why Vulkan was needed. While OpenGL did amazingly well to cope with the hardware evolutions, it was still designed over 20 years ago, This proved to have some core characteristics that are not really relevant any more, and are holding the application developers back. For example, he mentioned that at its core, OpenGL is based on a singleton-based state machine, that obviously doesn’t scale well anymore on our SMP systems. He also mentioned that it was too abstracted, and people just wanted a lower level API, or that you might want to render things off screen without X or any context.
This was fixed in Vulkan by effectively removing the state machine, which allows it to scale, push things like the error checking or the synchronization directly to the applications, making the implementation much simpler and less layered which also simplifies the development and debugging.
He then went on to discuss how we could share the code that was still shared between the two implementations, like implementing OpenGL on top of Vulkan (which was discarded), having some kind of lighter intermediate language in Mesa to replace Gallium or just sharing through a library the common bits and making both the OpenGL and Vulkan libraries use that.
Motivating preemptive GPU scheduling for real-time systems – Slides – Video
The last talk that we want to mention is the talk on preemptive scheduling by Roy Spliet, from the University of Cambridge.
More and more industries, and especially the automotive industry, offload some computations to the GPU for example to implement computer vision. This is then used in a car to implement the autonomous driving to make the car recognize signs or stay in its lane. And obviously, this kind of computations are supposed to be handled in a real time
system, since you probably don’t want your shiny user interface for the heating to make your car crash in the car before it because its rendering was taking too long.
He first started to explain what real time means, and what the usual metrics are, which should to no surprise to people used to “CPU based” real time systems: latency, deadline, execution time, and so on.
He then showed a bunch of benchmarks he used to test his preemptive scheduler, in a workload that was basically running OpenArena while running some computations, on various nouveau based platforms (both desktop-grade GPUs, and embedded SoCs).
This led to some expected conclusions, like the fact that a preemptive scheduler is indeed adding some overhead, but is on average worth it, while some have been quite interesting. He was for example observing some worst case latencies that were quite rare (0.3%), but were actually interferences from the display engine filling up its empty FIFOs, and creating some contention on the memory bus.
Conclusion
Overall, this has been a great experience. The organisation was flawless, and the one-track-only format allows you to meet easily both the speakers and attendees. The content was also highly technical, as you might expect, which made us learn a lot and led us to think about some interesting developments we could do on our various projects in the future, such as NextThing Co’s CHIP.
While developping a DMA controller driver for the Allwinner A31 SoCs (that eventually got merged in the 3.17 kernel), I’ve realised how under-documented the DMAEngine kernel subsystem was, especially for a newcomer like I was.
After discussing this with a few other kernel developers in the same situation, I finally started to work on such a documentation during the summer, and ended up submitting it at the end of July. As you might expect, it triggered a lot of questions, comments and discussions that enhanced a lot the documentation itself but also pointed out some inconsistencies in the API, obscure areas or just enhancements.
This also triggered an effort to clean up these areas, and hopefully, a lot more will follow, allowing to eventually clean up the framework as a whole.
And the good thing is that this documentation has been merged by the DMAEngine maintainer and is visible in linux-next, feel free to read it, and enhance it!
As the summer is coming to an end, we finally managed to publish the videos we recorded during the last Embedded Linux Conference, held earlier this year in San Jose, California.
This year, the Linux Foundation was only recording the audio of the talks, and we’ve been recording the video only for a few talks. Sorry to all the speakers that won’t be able to see their footage, but we were not able to attend (and record) all of the talks this year. Still, we include below the links to all the talks, slides and their audio recording, in order to cover all of this year’s schedule.
Part of the work on the CFA-10036 and its breakout boards was to write a driver that was using the FIQ mechanism provided by the ARM architecture to bitbang GPIOs on the first GPIO bank of the iMX28 port controller.
Abstract
FIQ stands for Fast Interrupt reQuest, and it is basically a higher priority interrupt. This means that it will always have precedence over regular interrupts, but also that regular interrupts won’t mask or interrupt an FIQ, while an FIQ will mask or interrupt any IRQ.
FIQs are usually not used by the Linux Kernel, yet some infrastructure is available to do everything you need to be able to use the FIQs in a driver. And since Linux only cares about the IRQs, it will never mess with the FIQs, allowing to achieve some hard real time constraints, without having to bother about the masked interrupts.
There are two more things to know about the FIQs. First, FIQs are executed in a dedicated execution mode, and this FIQ mode has 7 dedicated registers, from r8 to r14. This allows to have persistent values between each FIQ handler code, and avoids the overhead of pushing and popping in the handler. The second thing to know is that, unlike the regular IRQ handlers, the FIQ handler has to be written using ARM assembly, mostly because the C compiler won’t produce any code that can use only these r8 to r14 registers.
Practical case
In the CFA-10036 case, we wanted to bitbang a set of GPIOs at a programmable interval with a microsecond accuracy, and from a userspace application. The setup we chose was to make a large memory buffer of instructions available to userspace through mmap, and use a simple consumer/producer setup. An instruction was basically the interval to the next handler firing, which GPIOs values to clear, and which ones to set.
Step 1: Setup a timer
One thing to keep in mind is that basically, we will do many things behind the kernel’s back. So you won’t be able to use the standard kernel framework APIs from the FIQ handler. That means that we won’t be able to use the gpiolib, the regular timer API, etc. So you have to make sure to use either something that is not used at all by the kernel or something the kernel can deal with. The first thing to do then is to register a timer so that we can generate our FIQ on a regular basis. Here, we chose the third iMX28 timer, that is the first timer not used by the kernel. Of course, since it is device dependent and not using the kernel’s API, we had to do the timer initialization by hand in our driver.
We obviously made it generate an interrupt when it expires, and then had to poke into the iMX28 interrupt controller to generate a FIQ from this interrupt. How to achieve this is once again dependent on the hardware, and some architectures provide functions to do so (s3c24xx_set_fiq for Samsung’s Exynos, mxc_set_irq_fiq for Freescale’s IMX, etc.) while some others don’t, like it was the case for iMX28 (which is part of the MXS architecture), so we had to do it by hand once again in our driver.
Once this is done, we now have a timer that generates an FIQ on a regular basis. The second step will obviously be to register our handler for this FIQ.
Step 2: Register our handler
Registering an FIQ handler is actually quite simple. The first thing to do is actually to call the claim_fiq function, that mostly makes sure no other FIQ handler has already been registered.
The next step is to register your FIQ handler. This is done with the set_fiq_handler function. This function takes a pointer to the handler and the size of the handler code as argument, to basically memcpy your handler directly into the interrupt vector.
Most of the time, we would have something like below in our assembly code, and compute the handler size by the difference between the two labels.
my_handler:
handler code
my_handler_end:
Beware that it can get nasty, especially when you use a numeric constant that will get stored in a literal pool (for example when storing large variables into a register using LDR), if you don’t pay attention, the literal pool will be stored outside of the bounds you asked to copy, resulting in the value you use in the actual FIQ handler being garbage. We can also pre-set some register values that you will find in FIQ mode, typically to pass arguments to your handler, using the set_fiq_regs function.
The last step is obviously to enable the FIQ, using the enable_fiq function.
Once this is done, we have the basic infrastructure to process the data that will come from the shared buffer.
Step 3: Allocate the instruction buffer and share it
We needed a pretty large instruction buffer to share with userspace. We wanted to store about 1 million instructions in the buffer, each instruction taking 12 bytes (3 unsigned long integers), which makes around 12 MiB.
The usual allocation mechanism couldn’t be used, because __get_free_pages can only allocate up to 512 pages. Each page on ARM being of 4 KiB, this function is thus limited to 2 MiB.
So we chose to use CMA (Contiguous Memory Allocator) that was introduced in the 3.4 kernel, and is used precisely to allocate large chunk of contiguous memory. It achieves this by allocating a given size of movable pages at boot time, that will be used by the kernel as long as no one needs them, and will be reclaimed when a driver needs them. CMA is also used directly through the regular DMA API, so we’re in known territory.
The first thing to do to use CMA is to declare the memory region we want to reserve for our device in the device tree (we have been using the “Device tree support for CMA” patchset).
As you may know, the device tree is for hardware description and the CMA shouldn’t be in it at all, since it doesn’t describe the hardware in itself, but how we need to allocate the memory for a given piece of hardware. The chosen node is here exactly for that, since it will hold all the things the system needs, but doesn’t describe hardware. A similar case is the kernel command line. In our case, we add a subnode to chosen, with which amount of memory we should pre-allocate (0xc00000, which is 12 MiB, in our case), at which kernel address (0 in our case, since we basically don’t care about the base address of the buffer, we just want it to be there), and which device should use it.
Then, in our driver, we only need to call dma_alloc_coherent from our driver, and that’s it.
Now, we need to share this memory through mmap. This wouldn’t be a big deal, except for the caches. Indeed, the ARMv5 caches are virtually tagged, resulting in cache coherency problem when using two different virtual addresses pointing to the same physical address, which is exactly the situation we will be in.
We thus need to disable the cache on this particular mapping. This is done through a flag set with the pgprot_noncached function, that sets the page protection flags before calling the remap_pfn_range function in the mmap driver hook.
This should be ok by now, and you should be able to use the data inside the buffer from both sides now.
Step 4: Actual Results
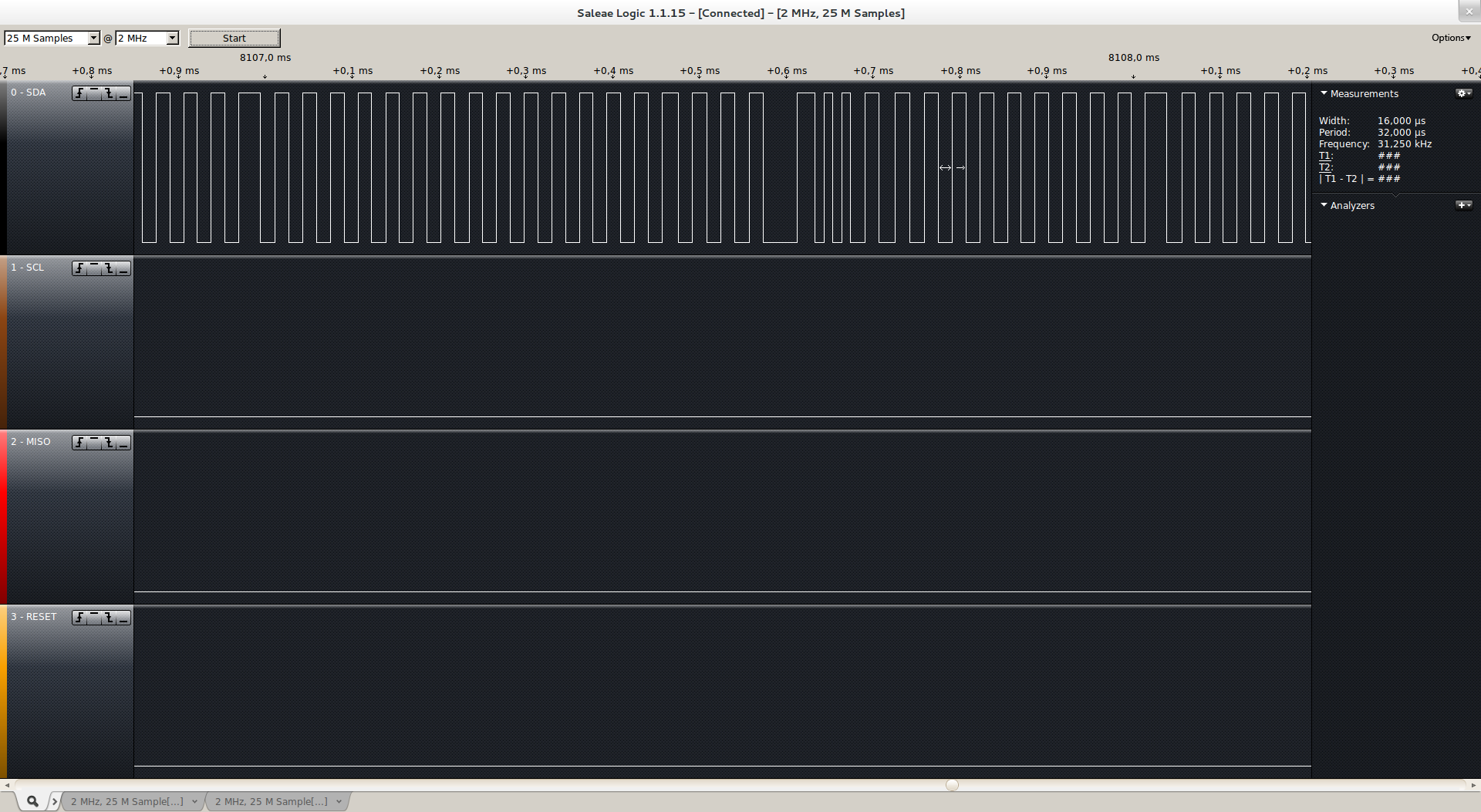
We here tried to generate a 50kHz square waveform by bitbanging the GPIOs both using a FIQ and using a regular IRQs, and here is the result (to emulate some load on the system, a dd if=/dev/zero of=/file was run when the captures were taken).
This is using regular IRQs. We can notice several thing wrong about this. The first one is pretty obvious, since we have a lot of jitter. The next one is that even though we requested a interval between each timer firing of 10microseconds, we here see that we are more around 16us, with quite a lot of latency.
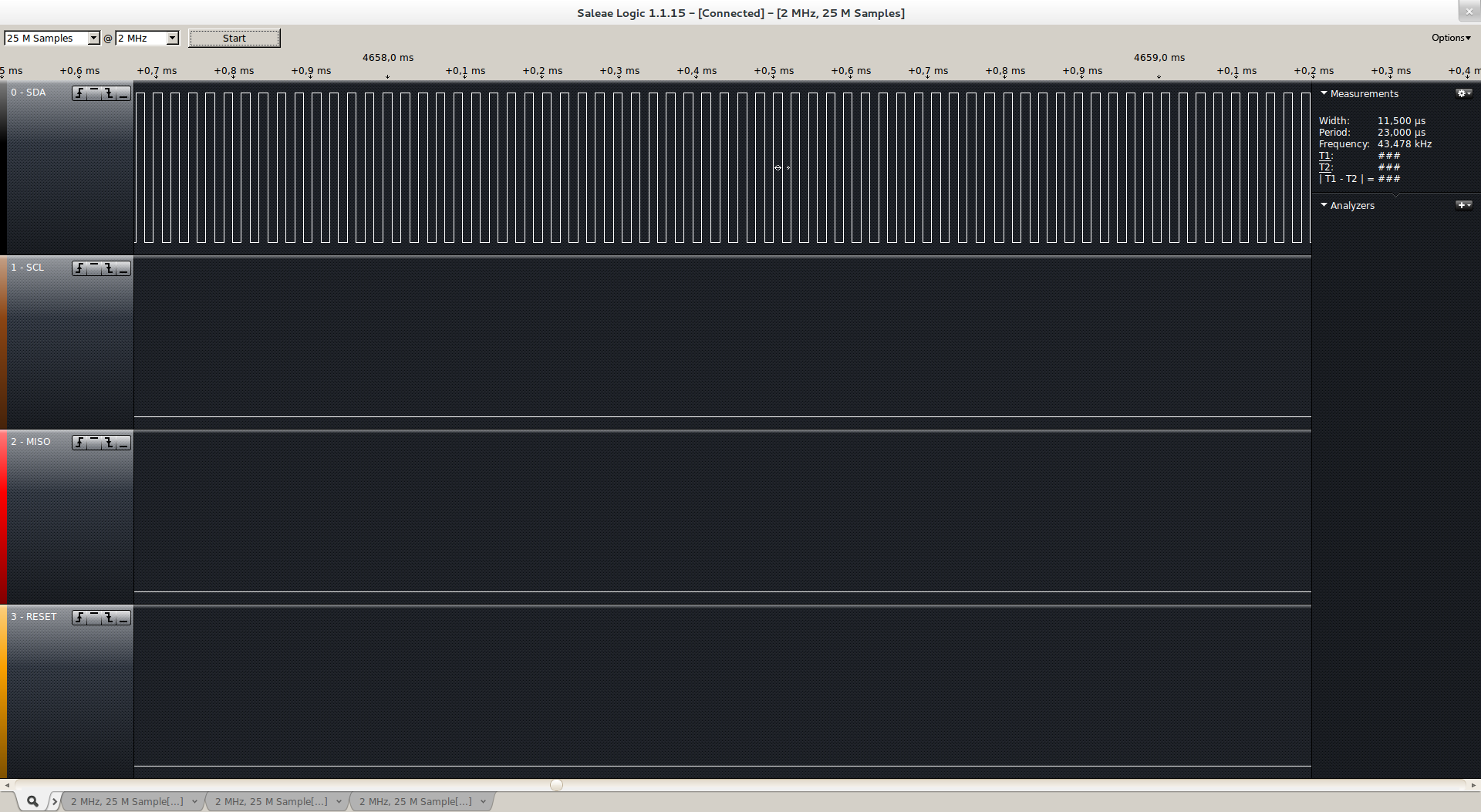
Now, here is what we get with an FIQ:
We can see that there’s no longer any jitter, the 50kHz square waveform we requested is almost perfectly output by our FIQ handler. We can notice however that there is still a constant ~1us latency, presumably because we had to reprogram the timer from our handler.
Final Words
Working on this FIQ thing has been really great, mostly because it involved several things I wasn’t used to, like CMA, or to make sure the kernel could deal with something changing behind its back. For example, we had to change slightly the imx28 gpio driver, because it was keeping an internal cache of the GPIO values it previously set, resulting in a pretty nasty behaviour when changing a GPIO value from the FIQ, and then controlling another one through the regular GPIO interface.
The application for this was to generate waveforms sent to stepper drivers, to control a 3D printer from the CFA-10036. You can watch the end result of all this work on Crystalfontz‘ Youtube channel, and especially on this video:
Finally, we can conclude that the FIQ can be an effective way to achieve near-real-time latencies, on a vanilla kernel without any RT patches.
Of course, you can find the whole code on Crystalfontz Github, most notably the driver, the handler and a small application demo for it.