It’s now Thursday morning here in Redwood City, California, and I didn’t had the time yesterday morning to do a write-up about our second day at the Android Builders Summit. Hopefully the following write-up will give our readers some details about what happened during this day.
This second of Android Builders Summit was co-located with the Yocto Developer Day, and as my colleagues Maxime Ripard and Grégory Clément were attending the two tracks of Android Builders Summit, I decided that I would attend the Yocto Developer Day.
Yocto Developer Day
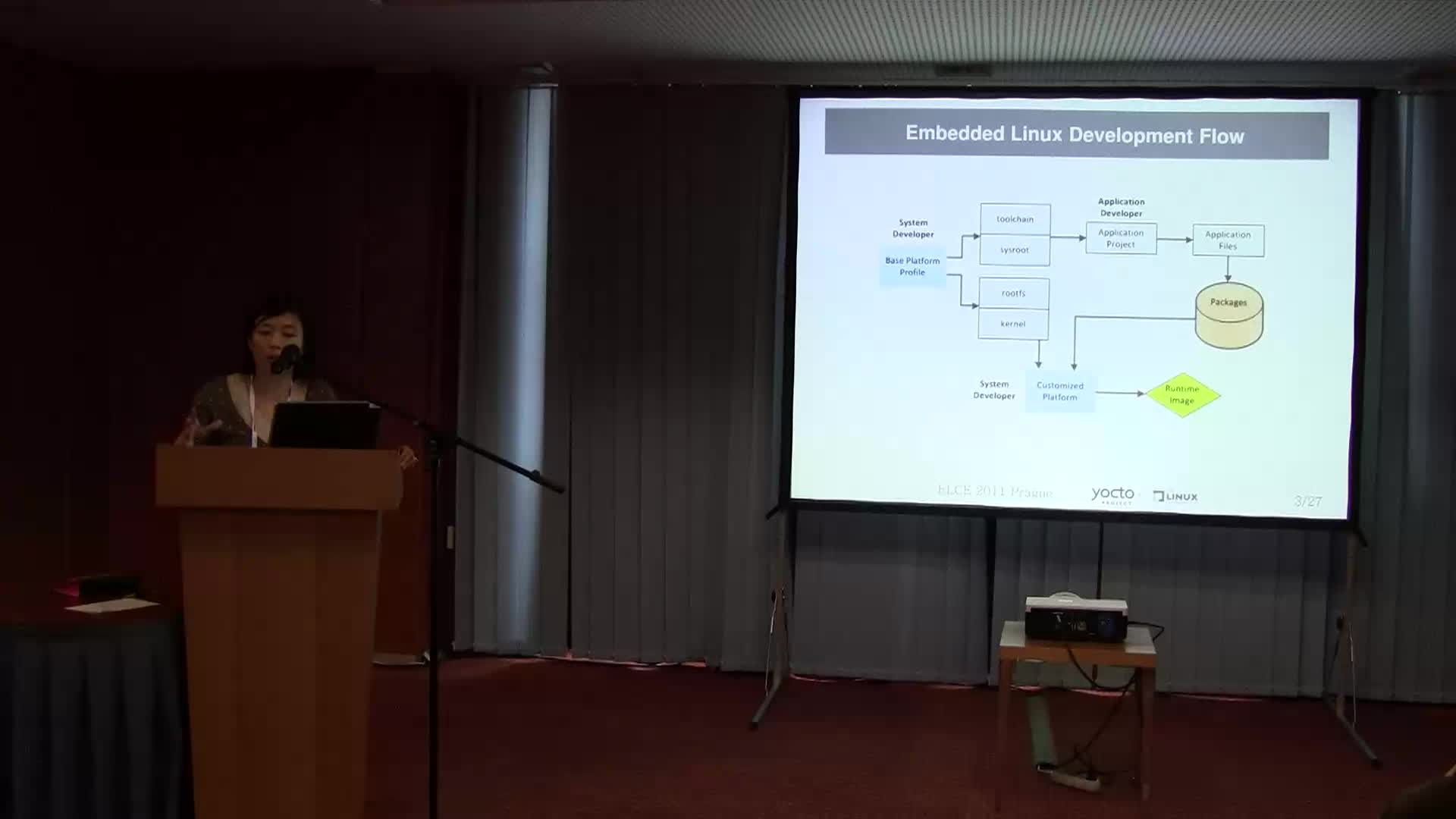
Yocto is an umbrella project that consists in creating an embedded Linux build system, called Poky and some associated development tools. Poky takes its roots into the OpenEmbedded community: it re-uses the bitbake recipe processor, and a set of recipes for building packages that are now shared between Yocto and OpenEmbedded through the openembedded-core repository. At Bootlin, we are strong contributors to the Buildroot build system, and we use it for many of our customer projects. However, being pushed very strongly by Intel and the Linux Foundation, Yocto is gaining traction, and the fact that Yocto provides stable releases every 6 months now makes it a lot more usable than OpenEmbedded, which had to be checked out through Git, leaving the user with the uncertainty on whether the version (s)he got would actually work or not. And moreover, Buildroot and Yocto are not really competing projects: Buildroot is a simple root filesystem image generator, while Yocto is more a cross-distribution generator, they target projects of different sizes.
I started attending the Yocto Developer Day with a general presentation talk about what Yocto is and why it is necessary. Nothing really new in this talk for someone who already uses embedded Linux build systems and understands the need for such tools. However, the thing that always surprises me is that the Yocto project claims everywhere to solve the fragmentation problem in the embedded Linux build system space (there are too many tools in this area) by creating the tool, and that they envision that in 5 years, everybody will link embedded Linux build with the Yocto project. It’s quite funny because at the moment, they have just created yet another build system 🙂 But it’s true that the project is gaining traction and seems to attract the SoC vendors, which is a good thing because having a standard build system is so much better than having crappy vendor-specific build systems.

The second talk, by Saul Wold, from Intel, went more into the details on how to use Yocto: what the different components are, how recipes are written, how configuration is defined, what tasks, images, recipes, etc are. I would have liked if the talk went a bit further into the details, but it gave a very good introduction to the Poky build system.
In the afternoon, I attended a hands-on session for new users to Yocto. The room setup was very impressive: about forty high-end PCs provided, each having a development board next to it. The first part of the hands-on session consisted in using Yocto to produce a basic filesystem image which we booted into Qemu. In order to solve the very long first build problem that all OpenEmbedded and Yocto users face, they had pre-built a number of packages and stored them into a shared state directory. Interestingly, the size of the Yocto output directory was about 30 GB, just to build an embedded Linux system with BusyBox and a few minor things. Once this was done, we went ahead in creating our own layer, in order to define our own image and its contents it terms of packages. We used it to add a graphical splashscreen, and I also extended it to include Dropbear into the build. The whole thing went quite well. One thing that worries me is that bitbake and the build process really looks like a black box, and it seems hard to understand what’s going on behind the scenes. With Buildroot, I am used to a very simple build system with which it is very easy to fully understand what’s going on. Here, even the people that give speeches about Yocto or deliver a bit of training, seem to not fully understand what’s going on. This impression is also validated by the complexity of the output directory (where all the build results are). But maybe it’s just a matter of spending some time using it and reading some code, but the fact that people that have been developing/using Yocto for a while still do not really understand its internals is a bit surprising. Or maybe it’s just a wrong impression on my side.

The next part of the hands-on was around the Eclipse integration of Yocto. First with ADT (Application Development Toolkit), which integrates the cross-development thing into Eclipse. Thanks to an agent running into the target, Eclipse is able to push the application binary to the target and start gdbserver on it, and therefore transparently start a debugging session for the user. I am not a big fan of Eclipse (I have been an Emacs user for a huge number of years), but it’s true that for people used to Integrated Development Environments, this ADT thing provides a quite nice experience. Then, we went ahead in trying to use HOB, which integrates into Eclipse the possibility of selecting which packages should be built and integrated into the image. Unfortunately, it seems it didn’t work for anybody (even though we were selecting the package in the GUI, it didn’t appear in the final filesystem image), but that wasn’t a big problem since I don’t really see the point in a tool such as HOB: editing configuration files is something that shouldn’t scare any embedded Linux developer.
Regardless of the contents of the hands-on, I was quite interested by how it was conducted. Instead of having some written lab instructions, and having everyone following, alone, those lab instructions, the instructor was simply demoing the various steps to be done on the video-projector screen, which we simply had to replicate. It makes the session quite interactive, with of course the drawback that everyone needs to progress at the same pace.
All in all, this Yocto Developer Day was interesting, and I hope to find some time soon to experiment further with Yocto.
Android Builders Summit
My colleagues attended multiple talks about Android during this second day of the conference. In the morning, they attended Headless Android, Towards a Standard Audio HAL for Android, Android on eMMC: Optimizing for Performance.

In the afternoon, Grégory attended the Real-Time Android talk, which he said, was interesting. It showed that it was possible to integrate the PREEMPT_RT patches together with the Android kernel modifications, and provide a system having real-time capabilities for native (C/C++) applications and still the nice aspect of the Android user interface. During the same slot, Maxime attended the Android Services Black Magic, given by Aleksandar (Saša) Gargenta from Marakana. As usual with the Gargenta brothers, the talk was highly interesting and gave a lot of detailed information about Android services.
Some other thoughts…
At the organization level, the conference organizers should make it clear in the conference program and flyer the location where the slides will be posted. At almost every talk there is someone that asked if and where the slides will be posted, and the speakers are sometimes a bit uncomfortable because there is no clearly identified place to post the slides. In the past years, it was made clear that the slides would be posted on the elinux.org wiki, but this year, things are very unclear. Moreover, it’s even more surprising since speakers are asked to post their slides into their Linux Foundation website account, but those slides are not being made visible. Maybe a good suggestion for the Linux Foundation would be to improve how slides are handled and posted online.
Another thought about the Android Builders Summit is the surprising absence of Google, the developer and maker of Android. Google sponsors the Embedded Linux Conference which takes place right after the Android Builders Summit, but they do not sponsor the Android Builders Summit. There is also no talk from Google developers, and I haven’t seen any Google person in the attendees. It’s even more surprising when we know that the conference takes place in a location about 18 minutes away by car from Google headquarters in Mountain View. Maybe Google doesn’t want to see Android being used in application areas other than phones and tablets?


 Bootlin is not in the system administration business (we offer free and open-source solutions for embedded systems), but we do our best to share whatever experience we acquire, and whatever code we produce.
Bootlin is not in the system administration business (we offer free and open-source solutions for embedded systems), but we do our best to share whatever experience we acquire, and whatever code we produce.

 As usual,
As usual,