Over the years, Bootlin has grown a significant expertise in U-Boot and Linux support for flash memory devices. Thanks to this expertise, we have recently been in charge of rewriting and upstreaming a driver for the Arasan NAND controller, which is used in a number of Xilinx Zynq SoCs. It turned out that supporting this NAND controller had some interesting challenges to handle its ECC engine peculiarities. In this blog post, we would like to give some background about ECC issues with NAND flash devices, and then dive into the specific issues that we encountered with the Arasan NAND controller, and how we solved them.
Ensuring data integrity
NAND flash memories are known to be intrinsically rather unstable: over time, external conditions or repetitive access to a NAND device may result in the data being corrupted. This is particularly true with newer chips, where the number of corruptions usually increases with density, requiring even stronger corrections. To mitigate this, Error Correcting Codes are typically used to detect and correct such corruptions, and since the calculations related to ECC detection and correction are quite intensive, NAND controllers often embed a dedicated engine, the ECC engine, to offload those operations from the CPU.
An ECC engine typically acts as a DMA master, moving, correcting data and calculating syndromes on the fly between the controller FIFO’s and the user buffer. The engine correction is characterized by two inputs: the size of the data chunks on which the correction applies and the strength of the correction. Old SLC (Single Level Cell) NAND chips typically require a strength of 1 symbol over 4096 (1 bit/512 bytes) while new ones may require much more: 8, 16 or even 24 symbols.
In the write path, the ECC engine reads a user buffer and computes a code for each chunk of data. NAND pages being longer than officially advertised, there is a persistent Out-Of-Band (OOB) area which may be used to store these codes. When reading data, the ECC engine gets fed by the data coming from the NAND bus, including the OOB area. Chunk by chunk, the engine will do some math and correct the data if needed, and then report the number of corrected symbols. If the number of error is higher than the chosen strength, the engine is not capable of any correction and returns an error.
The Arasan ECC engine
As explained in our introduction, as part of our work on upstreaming the Arasan NAND controller driver, we discovered that this NAND controller IP has a specific behavior in terms of how it reports ECC results: the hardware ECC engine never reports errors. It means the data may be corrected or uncorrectable: the engine behaves the same. From a software point of view, this is a critical flaw and fully relying on such hardware was not an option.
To overcome this limitation, we investigated different solutions, which we detail in the sections below.
Suppose there will never be any uncorrectable error
Let’s be honest, this hypothesis is highly unreliable. Besides that anyway, it would imply that we do not differentiate between written/erased pages and users would receive unclean buffers (with bitflips), which would not work with upper layers such as UBI/UBIFS which expect clean data.
Keep an history of bitflips of every page
This way, during a read, it would be possible to compare the evolution of the number of bitflips. If it suddenly drops significantly, the engine is lying and we are facing an error. Unfortunately it is not a reliable solution either because we should either trigger a write operation every time a read happens (slowing down a lot the I/Os and wearing out very quickly the storage device) or loose the tracking after every power cycle which would make this solution very fragile.
Add a CRC16
This CRC16 could lay in the OOB area and help to manually verify the data integrity after the engine’s correction by checking it against the checksum. This could be acceptable, even if not perfect in term of collisions. However, it would not work with existing data while there are many downstreams users of the vendor driver already.
Use a bitwise XOR between raw and corrected data
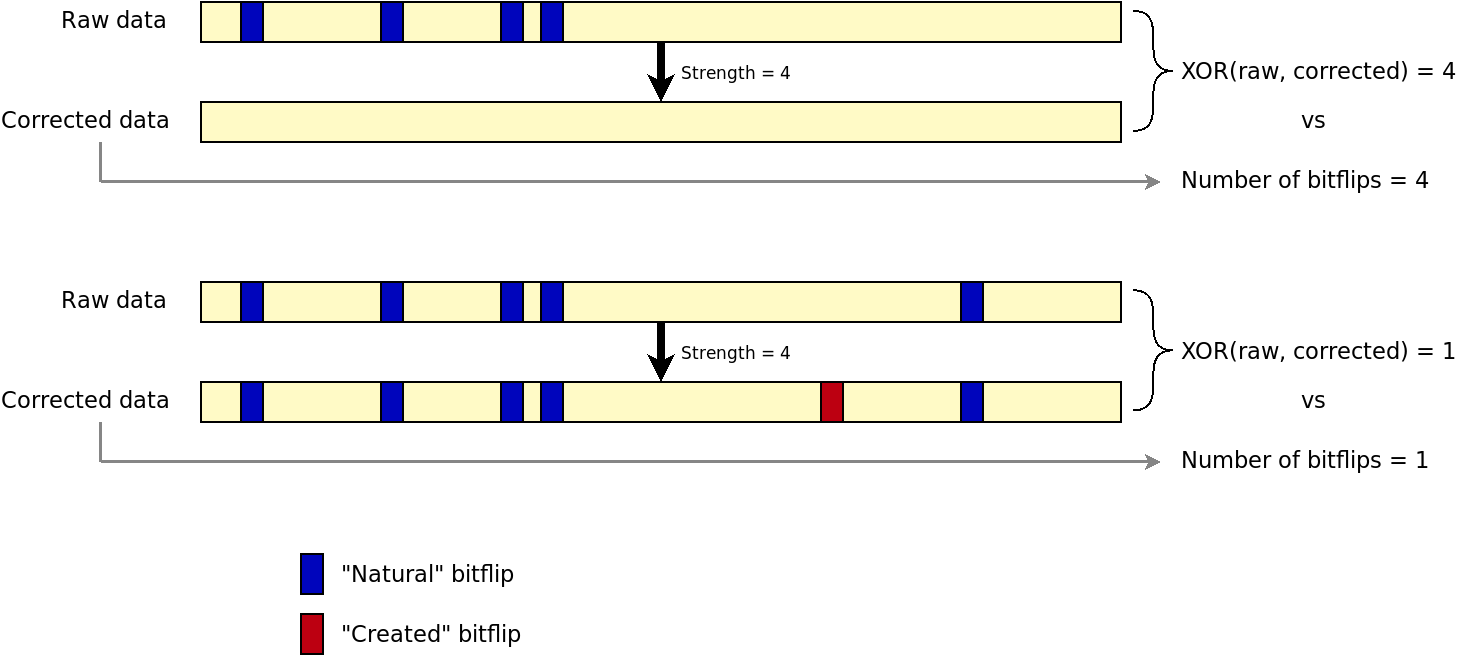
By doing a bitwise XOR between raw and corrected datra, and compare with the number of bitflips reported by the engine, we could detect if the engine is lying on the number of corrected bitflips. This solution has actually been implemented and tested. It involves extra I/Os as the page must be read twice: first with correction and then again without correction. Hence, the NAND bus throughput becomes a limiting factor. In addition, when there are too many bitflips, the engine still tries to correct data and creates bitflips by itself. The result is that, with just a XOR, we cannot discriminate a working correction from a failure. The following figure shows the issue.
Rely on the hardware only in the write path
Using the hardware engine in the write path is fine (and possibly the quickest solution). Instead of trying to workaround the flaws of the read path, we can do the math by software to derive the syndrome in the read path and compare it with the one in the OOB section. If it does not match, it means we are facing an uncorrectable error. This is finally the solution that we have chosen. Of course, if we want to compare software and hardware calculated ECC bytes, we must find a way to reproduce the hardware calculations, and this is what we are going to explore in the next sections.
Reversing a hardware BCH ECC engine
There is already a BCH library in the Linux kernel on which we could rely on to compute BCH codes. What needed to be identified though, were the BCH initial parameters. In particular:
The BCH primary polynomial, from which is derived the generator polynomial. The latter is then used for the computation of BCH codes.
The range of data on which the derivation would apply.
There are several thousands possible primary polynomials with a form like x^3 + x^2 + 1. In order to represent these polynomials more easily by software, we use integers or binary arrays. In both cases, each bit represents the coefficient for the order of magnitude corresponding to its position. The above example could be represented by b1101 or 0xD.
For a given desired BCH code (ie. the ECC chunk size and hence its corresponding Gallois Field order), there is a limited range of possible primary polynomials which can be used. Given eccsize being the amount of data to protect, the Gallois Field order is the smallest integer m so that: 2^m > eccsize. Knowing m, one can check these tables to see examples of polynomials which could match (non exhaustive). The Arasan ECC engine supporting two possible ECC chunk sizes of 512 and 1024 bytes, we had to look at the tables for m = 13 and m = 14.
Given the required strength t, the number of needed parity bits p is: p = t x m.
The total amount of manipulated data (ECC chunk, parity bits, eventual padding) n, also called BCH codeword in papers, is: n = 2^m - 1.
Given the size of the codeword n and the number of parity bits p, it is then possible to derive the maximum message length k with: k = n - p.
The theory of BCH also shows that if (n, k) is a valid BCH code, then (n - x, k - x) will also be valid. In our situation this is very interesting. Indeed, we want to protect eccsize number of symbols, but we currently cover k within n. In other words we could use the translation factor x being: x = k - eccsize. If the ECC engine was also protecting some part of the OOB area, x should have been extended a little bit to match the extra range.
With all this theory in mind, we used GNU Octave to brute force the BCH polynomials used by the Arasan ECC engine with the following logic:
Write a NAND page with a eccsize-long ECC step full of zeros, and another one full of ones: this is our known set of inputs.
Extract each BCH code of p bits produced by the hardware: this is our known set of outputs.
For each possible primary polynomial with the Gallois Field order m, we derive a generator polynomial, use it to encode both input buffers thanks to a regular BCH derivation, and compare the output syndromes with the expected output buffers.
Because the GNU Octave program was not tricky to write, we first tried to match with the output of Linux software BCH engine. Linux using by default the primary polynomial which is the first in GNU Octave’s list for the desired field order, it was quite easy to verify the algorithm worked.
As unfortunate as it sounds, running this test with the hardware data did not gave any match. Looking more in depth, we realized that visually, there was something like a matching pattern between the output of the Arasan engine and the output of Linux software BCH engine. In fact, both syndromes where identical, the bits being swapped at byte level by the hardware. This observation was made possible because the input buffers have the same values no matter the bit ordering. By extension, we also figured that swapping the bits in the input buffer was also necessary.
The primary polynomial for an eccsize of 512 bytes being already found, we ran again the program with eccsize being 1024 bytes:
With the two possible primary polynomials in hand, we could finish the support for this ECC engine.
At first, we tried a “mixed-mode” solution: read and correct the data with the hardware engine and then re-read the data in raw mode. Calculate the syndrome over the raw data, derive the number of roots of the syndrome which represents the number of bitflips and compare with the hardware engine’s output. As finding the syndrome’s roots location (ie. the bitflips offsets) is very time consuming for the machine it was decided not to do it in order to gain some time. This approach worked, but doing the I/Os twice was slowing down very much the read speed, much more than expected.
The final approach has been to actually get rid of any hardware computation in the read path, delegating all the work to Linux BCH logic, which indeed worked noticeably faster.
The overall work is now in the upstream Linux kernel:
If you’re interested about more details on ECC for flash devices, and their support in Linux, we will be giving a talk precisely on this topic at the upcoming Embedded Linux Conference!
Bootlin engineer Boris Brezillon has been involved in the support for NAND flashes in the Linux kernel for quite some time. He is the author of the NAND driver for the Allwinner ARM processors, did several improvements to the NAND GPMI controller driver, has initiated a significant rework of the NAND subsystem, and is working on supporting MLC NANDs. Boris is also very active on the linux-mtd mailing list by reviewing patches from others, and making suggestions.
For those reasons, Boris was recently appointed by the MTD maintainer Brian Norris as a new maintainer of the NAND subsystem. NAND is considered a sub-subsystem of the MTD subsystem, and as such, Boris will be sending pull requests to Brian, who in turn is sending pull requests to Linus Torvalds. See this commit for the addition of Boris as a NAND maintainer in the MAINTAINERS file. Boris will therefore be in charge of reviewing and merging all the patches touching drivers/mtd/nand/, which consist mainly of NAND drivers. Boris has created a nand/next branch on Github, where he has already merged a number of patches that will be pushed to Brian Norris during the 4.7 merge window.
We are happy to see one of our engineers taking another position as a maintainer in the kernel community. Maxime Ripard was already a co-maintainer of the Allwinner ARM platform support, Alexandre Belloni a co-maintainer of the RTC subsystem and Atmel ARM platform support, Grégory Clement a co-maintainer of the Marvell EBU platform support, and Antoine Ténart a co-maintainer of the Annapurna Labs platform support.
Note: this article was first written for the German edition of Linux Magazine, and was later posted in the English edition too. We negotiated the right to publish it on our blog after the print editions. Here is the original version (the paper versions were modified by the editors to make them more concise).
In the family tree of computers, personal computers (PCs) are the parents, while the children and teenagers are mobile devices. PCs are no longer physically attractive, getting close to retirement. They produce a lot of heat, and make all sorts of unpleasant noise when you are next to them. Noise is caused by keyboard presses, by fans that are essential to avoid computer meltdown, and by rotating disks that sound like nothing but something that rotates.
The last chance for this generation to survive a few more years is to send them to a remote place where nobody can see their old bodies and hear their annoying noise any more. This place is called The Cloud. Perhaps because it gets these systems closer to the final destination: heaven.
If you have a device that you feel like putting on your knees (without getting burned) and caress its skin (oops screen), and doesn’t make any noise but the pleasant sounds that you feel like listening too, chances are you have a device from the last generation.
One reason why your device doesn’t make any unwanted sound is because it doesn’t have rotating disks, but flash storage instead. Most modern devices have flash storage, and most of these devices run Linux. This article gives technical details about how Linux supports flash storage devices. It should mostly interest people creating embedded and multimedia devices using the Linux kernel to get the best performance out of their hardware. People who wish to hack the devices they own should be interested too.
Flash storage
Flash storage, also called solid state, has multiple advantages over rotating storage. First, the absence of mechanical and moving parts eliminate noise, increase reliability and resistance to shock and vibrations, and also reduces heat dissipation as well as power consumption. Second, random access to data is also much faster, as you no longer have to move a disk head to the right location on the medium, which can take milliseconds.
Flash also has its shortcomings, of course. First, for the same price, you have about 10 times less solid state storage than rotating storage. This can be an issue with operating systems that require Gigabytes of disk space. Fortunately, Linux only needs a few MB of storage. Second, writing to flash storage has special constraints. You cannot write to the same location on a flash block multiple times without erasing the entire block, called an “erase block”. This constraint can also cause write speed to be much lower than read speed. Third, flash blocks can only withstand a rather limited number of erases (from a few thousand for today densest NAND flash to one million at best). This requires to implement hardware or software solutions, called “wear leveling”, to make sure that no flash block gets written to much too often that the others.
NOR flash was the first type of flash storage that was invented. NOR is very convenient as it allows the CPU to access each byte one by one, in random order. This way, the CPU can execute code directly from NOR flash. This is very convenient for bootloaders, which do not have to be copied to RAM before executing their code.
NAND flash is today’s most popular type of flash storage, as it offers more storage capacity for a much lower cost. The drawback is that NAND storage is on an external device, like rotating storage. You have to use a controller to access device data, and the CPU cannot execute code from NAND without copying the code to RAM first. Another constraint is that NAND flash devices can come out of the factory with faulty blocks, requiring hardware or software solutions to identify and discard bad blocks.
Two types of NAND flash storage are available today. The first type emulates a standard block interface, and contains a hardware “Flash Translation Layer” that takes care of erasing blocks, implementing wear leveling and managing bad blocks. This corresponds to USB flash drives, media cards, embedded MMC (eMMC) and Solid State Disks (SSD). The operating system has no control on the way flash sectors are managed, because it only sees an emulated block device. This is useful to reduce software complexity on the OS side. However, hardware makers usually keep their Flash Translation Layer algorithms secret. This leaves no way for system developers to verify and tune these algorithms, and I heard multiple voices in the Free Software community suspecting that these trade secrets were a way to hide poor implementations. For example, I was told that some flash media implemented wear leveling on 16 MB sectors, instead of using the whole storage space. This can make it very easy to break a flash device.
The second type is raw flash. The operating system has access to the flash controller, and can directly manage flash blocks. Counting the number of times a block has been erased is also possible (“block erase count”). The Linux kernel implements a Memory Technology Device (MTD) subsystem that allows to access and control the various types of flash devices with a common interface. This gives the freedom to implement hardware independent software to manage flash storage, in particular filesystems. Freedom and independence is something we have learned to care about in our community.
The Linux MTD architecture
Linux MTD partitions
The first thing you can do is access raw flash storage and partitions. It is similar to accessing raw block devices through devices files like /dev/sda (whole device) and /dev/sda1, /dev/sda2, etc. (partitions).
MTD devices are usually partitioned. This is useful to define areas for different purposes, such as:
Example MTD partitions
Raw means that no filesystem is used. This is not needed when you just have one binary to store, instead of multiple files.
Declaring partitions as read-only is also a way to make sure that Linux won’t allow to make changes to such partitions. This way, the bootloader and root filesystem partitions can be protected against mistakes and unauthorized modification attempts. You can also note that partitions cannot be bypassed by accessing the whole device at a given offset, as Linux offers no device file to access the whole storage.
What’s special in MTD partitions is that there is no partition table as in block devices. This is probably because flash is an unsafe location to store such critical system information, as flash blocks may become bad during system life.
Instead, partitions are defined in the kernel. An example is found in the arch/arm/mach-omap2/board-omap3beagle.c file in the kernel sources, defining flash partitions for the Beagle board:
Fortunately, you can override these default definitions without having to modify the kernel sources.
You first need to find the name of the MTD device to partition, as you may have multiple ones. Look at the
kernel log at boot time. In the Beagle board example, the MTD device name is omap2-nand.0:
Fortunately, you can define your own partitions without having to modify the kernel sources. The Linux kernel offers an mtdpartss boot parameter to define your own partition boundaries.
You can now add an mtdparts definition to the kernel command line (change it through the bootloader):
We have just defined 6 partitions in the omap2-nand.0 device:
First stage bootloader (128 KiB, read-only)
U-Boot (256 KiB, read-only)
U-Boot environment (128 KiB)
Kernel (4 MiB, read-only)
Root filesystem (16 MiB, read-only)
Data (remaining space)
Note that partition sizes must be a multiple of the erase block size. The erase block size can be found in /sys/class/mtd/mtdx/erasesize on the target system.
Now that partitions are defined, you can display the corresponding MTD devices by viewing /proc/mtd (the sizes are in hexadecimal):
Here, you can also see another difference with block devices. Device files names for block device partitions still refer to the complete device name (for example /dev/sda1 for the first partition of the device represented by /dev/sda). MTD partitions are shown as independent MTD devices, and for example mtd1 could either be the second partition of the first flash device, or the first partition of the second flash device. You cannot tell the difference from device names.
Back to our example, you can see that a separate flash partition is dedicated to storing the U-Boot environment variables. Did you know that you can update these variables from Linux, by flashing an image for this partition? At Bootlin, we have contributed a utility to create such an image.
Manipulating MTD devices
You can access MTD device number X through two types of interfaces. The first interface is a /dev/mtdX character device, managed by the mtdchar driver. In particular, this character device provides ioctl commands that are typically used by mtd-utils commands to manipulate and erase blocks in an MTD device.
The second interface is a /dev/mtdblockX block device, handled by the mtdblock driver. This device is mostly used to mount MTD filesystems, such as JFFS2 and YAFFS2, because the mount command primarily works with block devices. You may be tempted to use this device to write to the MTD device, but the corresponding driver isn’t elaborate enough for use in production. When you attempt to write to a given block, the previous contents are copied to RAM, the MTD block is erased, and the updated contents are written to the block. As you can see, there is no wear leveling of any sort, as a series of writes to the same part of the block device could very quickly damage the corresponding erase blocks. Worse, mtdblock isn’t even bad block aware. If you copy a filesystem image directly to /dev/mtdblockX, and your NAND storage has bad blocks, your filesystem will be corrupted because of the failure to write parts of the filesystem image.
Therefore, the clean way to manipulate MTD devices is through the character interface, and using the mtd-utils commands. Here are the most common ones:
mtdinfo to get detailed information about an MTD device
flash_eraseall to completely erase a given MTD device
These commands are available through the mtd-utils package in GNU/Linux distributions and can also be cross-compiled from source by embedded Linux build systems such as Buildroot and OpenEmbedded. Simple implementations of the most common commands are also available in BusyBox, making them much easier to cross-compile for simple embedded systems.
JFFS2
Journaling Flash File System version 2 (JFFS2), added to the Linux kernel in 2001, is a very popular filesystem for flash storage. As expected in a flash filesystem, it implements bad block detection and management, as well as wear leveling. It is also designed to stay in a consistent state after abrupt power failures and system crashes. Last but not least, it also stores data in compressed form. Multiple compressing schemes are available, according to whether matters more: read/write performance or the compression rate. For example, zlib compresses better than lzo, but is also much slower.
Implementing flash filesystems has special constraints. When you make a change to a particular file, you shouldn’t just go the easy way and copy the corresponding blocks to RAM, erase them, and flash the blocks with the new version. The first reason is that a power failure during the erase or write operations would cause irrecoverable data loss. The second reason is that you could quickly wear out specific blocks by making multiple updates to the same file.
Another solution is to copy the new data to a new block, and replace references to the old block by references to the new block. However, this implies another write on the filesystem, causing more references to be modified until the root reference is reached.
JFFS2 uses a log-structured approach to address this problem. Each file is described through a “node”, describing file metadata and data, and each node has an associated version number. Instead of making in-place changes, the idea is to write a more recent version of the node elsewhere in an erase block with free space. While this simplifies write operations, this complicates read ones, as reading a file requires to find the most recent node for this file.
To optimize performance, JFFS2 keeps an in-memory map of the most recent nodes for each file. However, this requires to scan all the nodes at mount time, to reconstitute this map. This is very expensive, as JFFS2’s mount time is proportional to the number of nodes. Embedded systems using JFFS2 on big flash partitions incurred big boot time penalties because of this. Fortunately, a CONFIG_JFFS2_SUMMARY kernel option was added, allowing to store this map on the flash device itself and dramatically reduce mount time. Be careful, this option is not turned on by default!
Back to node management, older nodes must be reclaimed at some point, to keep space free for newer writes. A node is created as “valid” and is considered as “obsolete” when a newer version is created. JFFS2 managed three types of flash blocks:
Clean blocks, containing only valid nodes
Dirty blocks, containing at least one obsolete node
Free blocks, not containing any node yet
JFFS2 runs a garbage collector in the background that recycles dirty blocks into free blocks. It does this by collecting all the valid nodes in a dirty block, and copying them to a clean block (with space left) or to a free block. The old dirty block is then erased and marked as free. To make all the erase blocks participate to wear leveling, the garbage collector occasionally consumes clean blocks too. See Wikipedia for more details about JFFS2.
There are two ways of using JFFS2 on a flash partition. The first way is to erase the partition and format it for JFFS2, and then mount it:
flash_eraseall -j /dev/mtd2
mount -t jffs2 /dev/mtdblock2 /mnt/flash
Note that flash_eraseall -j both erases the flash partition and formats it for JFFS2. You can then fill the partition by writing data into it.
The second way, which is more convenient to program production devices, is to prepare a JFFS2 image on a development workstation, and flash this image into the partition:
To prepare the JFFS2 image, you need to use the mkfs.jffs2 command supplied by mtd-utils. Do not be confused by its name: unlike some other mkfs commands, it doesn’t create a filesystem, but a filesystem image.
You first need to find the erase block size (as explained earlier). Let us assume it is 256 MiB.
-d specifies is a directory with the filesystem contents
--pad allows to create an image which size is a multiple of the erase block size.
--no-cleanmarkers should only be used for NAND flash.
It is fine to have a JFFS2 image that is smaller than the MTD partition. JFFS2 will still be able to use the whole partition, provided it was completely erased ahead of time.
Note that to prepare production devices, it is much more convenient to flash your MTD partitions from the bootloader, using a bad block aware command, without having to boot Linux. This way, you do not have to put development utilities such as flash_eraseall in the Linux root filesystem. This is another reason why filesystem images are useful. You typically download the filesystem image to RAM through the network, and then copy the image to flash. When you do this, just make sure that you copy the exact image size. With kernel images, we often copy a bigger number of bytes from RAM to flash, as the exact image size can vary, and this creates no issue. With JFFS2 images, if you copy more bytes from RAM to flash, you will end up writing flash with random bytes from RAM after the end of your image, which will corrupt the filesystem. I’m warning you because this is a typical mistake the people make during our training sessions.
YAFFS2
YAFFS2 is Yet Another Flash Filesystem which apparently was created as an alternative to JFFS2. It doesn’t use compression, but features a much faster mount time, as well as better read and write performance than JFFS2. YAFFS2 is available with a dual GPL and Proprietary license, GPL for use in the Linux kernel, and proprietary for proprietary operating systems. Revenue from the proprietary license allowed the fund the development of this filesystem.
YAFFS2 less popular than JFFS2, and this is probably because it is not part of the mainline Linux kernel. Instead, it is available as separate code with scripts to patch most versions of the Linux kernel source. There was an effort to get it mainlined about one year ago, but this attempt failed because the changes the kernel maintainers asked for would have broken the portability to other operating systems, and therefore would have compromised the project business model.
To use YAFFS2 after patching your kernel, you just need to erase your partition:
flash_eraseall /dev/mtd2
The filesystem is automatically formatted at the first mount:
mount -t yaffs2 /dev/mtdblock2 /mnt/flash
It is also possible to create YAFFS2 filesystem images with the mkyaffs tool, from yaffs-utils.
UBI and UBIFS
JFFS2 and YAFFS2 had a major issue: wear leveling was implemented by the filesystems themselves, implying that wear leveling was only local to individual partitions. In many systems, there are read-only partitions, or at least partitions that are very rarely updated, such as programs and libraries, as opposed to other read-write data areas which get most writes. These “hot” partitions take the risk of wearing out earlier than if all the flash sections participated in wear leveling. This is exactly what the Unsorted Block Images (UBI) project offers.
UBI is a layer on top of MTD which takes care of managing erase blocks, implementing wear leveling and bad block management on the whole device. This way, upper layers no longer have to take care of these tasks by themselves. UBI also supports flexible partitions or volumes, which can be created and resized dynamically, in a way that is similar to the Logical Volume Manager for block devices.
UBI works by implementing “Logical Erase Blocks” (LEBs), mapping to “Physical Erase Blocks” (PEBs). The upper layers only see LEBs. If an LEB gets written to too often, UBI can decide to swap pointers, to replace the “hot” PEB by a “cold” one. This mechanism requires a few free PEBs to work efficiently, and this overhead makes UBI less appropriate for small devices with just a few MB of space.
UBI Physical and Logical Erase Blocks
UBIFS is a filesystem for UBI. It was created by the Linux MTD project as JFFS2’s successor. It also supports compression and has much better mount, read and write performance.
The first way to use UBIFS is to initialize UBI from Linux:
Have /dev/ mounted as a devtmpfs filesystem
Erase your flash partition while preserving your erase counters
ubiformat /dev/mtd1
Attach UBI to one (of several) of the MTD partitions:
ubiattach /dev/ubi_ctrl -m 1
This command creates the ubi0 device, which represents the full UBI space stored on MTD device 1 (interfaced by a new /dev/ubi0 character device).
Create one or several volumes as in the below examples:
ubimkvol /dev/ubi0 -N test -s 116MiB
ubimkvol /dev/ubi0 -N test -m (max available size)
Mount an empty UBIFS filesystem on the new test volume:
mount -t ubifs ubi0:test /mnt/flash
You can then fill the filesystem by copying files to it
Note that it is also possible to create a UBIFS filesystem image with the mkfs.ubifs command and copy the image using ubiupdatevol.
The second way is to create an image of the entire UBI space, which can be flashed from the bootloader by a bad block aware command. To do this, first create a ubi.ini file describing the UBI space, its volumes and their contents. Here is an example:
You can then create the UBI image, for example specifying 128 KiB physical erase blocks and a minimum I/O size of 4096 bytes:
ubinize -o ubi.img -p 128KiB -m 4096 ubi.ini
The last steps are to flash the image file from the bootloader, using a bad block aware command, and add some parameters to the kernel command line:
ubi.mtd=1 (equivalent to ubiattach)
rootfstype=ubifs root=ubi0:rootfs if you use the UBIFS volume as root filesystem.
LogFS
As its name says, LogFS is another log-structured flash filesystem. It has an innovative design that could compete with UBIFS, and is now part of the mainline Linux kernel since version 2.6.34.
Unfortunately, the last time we tested it, LogFS was unstable and caused kernel oopses at unmount time. Therefore, we couldn’t compare it with the other filesystems. Being in the mainline Linux sources makes its code easier to maintain and fix though, and the bugs may be fixed in the latest kernel version when you read this article.
More details about LogFS can be found on Wikipedia.
SquashFS
For read-only partitions, it is actually possible to use the SquashFS block filesystem on MTD devices. My first idea was to directly copy a SquashFS image to the corresponding /dev/mtdblockx device. After all, this filesystem is read-only, and you don’t need any wear-leveling of any kind, as you never make any write. This worked very well, and I got very good performance results, until I tried to use SquashFS on a device that happened to have bad blocks. Remember that the mtdblock driver isn’t bad block aware. As a consequence, the SquashFS images didn’t get copied properly and the filesystem was corrupted. A bad block aware block device was therefore required.
There are two ways to do this. It is first possible to use the gluebi driver that emulates an MTD device on top of a UBI volume. As UBI discards bad blocks, it is then safe to use the mdtblock driver on top of this new MTD device.
A second possibility is to use the ubiblock driver (first submitted to the Linux Kernel Mailing List in 2011 by Bootlin, and revived by Ezequiel Garcia in November 2012, which implements a block device directly on top of UBI. Our benchmarks showed that this is a more efficient solution, as it doesn’t have to emulate an intermediate MTD device).
Benchmarks
Bootlin has run performance benchmarks to compare the various flash filesystems, with funding from the Linux foundation. The benchmarks and their results are described on eLinux.org.
These benchmarks showed that JFFS2 has the worst performance, and must absolutely be compiled with CONFIG_SUMMARY to have an acceptable boot time. However, JFFS2 is still the best compromise for devices with small flash partitions, for which compression is required, and where UBI would have too much space overhead. This is the reason why JFFS2 is still in use in OpenWRT, a distribution mainly targeting embedded devices like residential gateways and routers, with typically 4 to 16 MB of flash storage.
YAFFS2, thanks to improvements in the last years, shows very good if not best performance in many test scenarios. However, its drawbacks remain the lack of compression and its absence from the mainline Linux kernel sources. It also has weird performance issues managing directories.
UBIFS is now the best solution in terms of performance and space, except for small partitions in which its space overhead is significant. Its only drawback is that it requires a bit more work to deploy, compared to the other filesystems.
At the time of this writing, LogFS is too experimental to be used in production systems, though you can expect its bugs to be fixed over time, as its code is in the mainline kernel sources.
Last but not least, SquashFS can also be used on MTD flash, in systems with read-only partitions. This filesystem exhibits good compression, good mount time, and good read performance as well. The requirement to use SquashFS on top of UBI impairs its mount time performance though. On block filesystems, SquashFS exhibits the best mount time, but it looses a lot of time when it is on top of UBI, which takes a substantial amount of time to initialize (ubiattach operation).
The good news is that it is very cheap to switch filesystems. Applications won’t notice the difference. As our benchmarks have shown, you may get noticeable performance results, according to the size of your partitions, to the size and number of files, to the read and write patterns of your system, and to whether your files can be compressed or not. All you have to do is try the various filesystems, run your application and system tests, and keep the solution that maximizes performance for your particular system.
Back to flash storage with a block interface
We have seen the MTD subsystem and several filesystems allowing for complete control on the way flash blocks are managed. This allows to choose the wear leveling and block management scheme that best matches the various characteristics of the system.
But what to do when you are stuck with flash storage with a block interface, like SD cards for example? With these devices, you have no details about the erase block size and about the wear leveling algorithm. While these media are fine for external storage which just get occasional writes, you may run into deep trouble if you use these as primary storage in a system with intense I/O operations.
This issue is getting all the more critical as NAND flash is being replaced by eMMC in many recent embedded boards. eMMC is NAND flash with an MMC interface, but as opposed to MMC, is soldered on the board, to be immune from reliability issues caused by vibrations. The main advantage of eMMC is its unit price, making it more attractive than individual NAND chips produced in smaller quantities. Another advantage is that the block device is immediately available at boot time, without requiring any intervention and scanning from the operating system. Not having to manage bad blocks and wear leveling also keeps software simpler, of course at the cost of less control as we said. Some board makers, for example the engineers at CALAO Systems, even predict the extinction of raw flash in the next years. Raw flash may just be kept for specific industrial applications, but would then get very expensive because of low production volume.
Fortunately, we are not completely stuck with no clue about the internals of such flash devices. Arnd Bergmann has studied cheap flash media and has developed flashbench, a benchmarking tool to find their erase block size. This allows to optimize file system settings and get huge performance boosts on these flash media, and reduce the number of block erases. Arnd has described is work in a very interesting article on LWN.net.
Other than that, you are still stuck with an opaque wear leveling mechanism, and it’s always wise to use techniques to minimize the number of writes:
Do not put a swap area on flash storage
Whenever possible, mount your filesystems as read-only, or use read-only filesystems (SquashFS)
Keep volatile files such as log files and locks in RAM (tmpfs). You do not need to keep them across reboots anyway, and you do not want to create unnecessary disk activity because of them.
Conclusions and what to remember
If you develop or hack a device with raw flash, your best option is to use the JFFS2 filesystem for small partitions, with the CONFIG_SUMMARY option. For medium to very large partitions, UBIFS will be the best compromise in terms of speed, size and boot time. However, you may get slightly better performance with YAFFS2, but at the expense of size.
If you have a device with only flash storage with a block interface, for example an SD card, download flashbench from Arnd Bergmann and optimize the settings of your filesystems to get the best performance out of your storage, and optimize its lifetime.
If you reached this part of the article, you have the patience and interest required to contribute to the MTD subsystem of the Linux kernel. Contributions, code reviews and new ideas are welcome!
Many embedded devices these days use the U-Boot bootloader. This bootloader stores its configuration into an area of the flash called the environment that can be manipulated from within U-Boot using the printenv, setenv and saveenv commands, or from Linux using the fw_printenv and fw_setenv userspace utilities provided with the U-Boot source code.
This environment is typically stored in a specific flash location, defined in the board configuration header in U-Boot. The environment is basically stored as a sequence of null-terminated strings, with a little header containing a checksum at the beginning.
While this environment can easily be manipulated from U-Boot or from Linux using the above mentioned commands, it is sometimes desirable to be able to generate a binary image of an environment that can be directly flashed next to the bootloader, kernel and root filesystem into the device’s flash memory. For example, on AT91 devices, the SAM-BA utility provided by Atmel is capable of completely reflashing an AT91 based system connected through the serial port of the USB device port. Or, in factory, initial flashing of devices typically takes place either through specific CPU monitors, or through a JTAG interface. For all of these cases, having a binary environment image is desirable.
David Wagner, who has been an intern with us at Bootlin from April to September 2011, has written a utility called mkenvimage which just does this: generate a valid binary environment image from a text file describing the key=value pairs of the environment. This utility has been merged into the U-Boot Git repository (see the commit) and will therefore be part of the next U-Boot release.
With mkenvimage you can write a text file uboot-env.txt describing the environment, like:
The -s option allows to specify the size of the image to create. It must match the size of the flash area reserved for the U-Boot environment. Another option worth having in mind is -r, which must be used when there are two copies of the environment stored in the flash thanks to the CONFIG_ENV_ADDR_REDUND and CONFIG_ENV_SIZE_REDUND. Unfortunately, U-Boot has chosen to have a different environment layout in those two cases, so you must tell mkenvimage whether you’re using a redundant environment or a single environment.
This utility has proven to be really useful, as it allows to automatically reflash a device with an environment know to work. It also allows to very easily generate a different environment image per-device, for example to contain the device MAC address and/or the device serial number.
Embedded-oriented filesystems are a scattered world. Flash-optimized filesystems are less so. JFFS2 has been widely used but has several performance issues (mount time, especially, though CONFIG_SUMMARY and sumtool fixes that since 2.6.15). LogFS doesn’t seem to be actively maintained. The most active and promising flash filesystem is UBIFS. It runs on top of UBI (“Unsorted Block Images”), an abstraction layer for MTD devices.
Why flash-oriented filesystems ?
MTDs (Memory Technology Devices) are very different from block devices: instead of a sequence of writable sectors, they contain an array of writable pages, organized in so-called “erase blocks”.
To write on a page that already has data on it, you first have to erase this data. However, it is only possible to erase whole eraseblocks. Only then, you can write your new data (including what you didn’t change). Erasing causes the memory cells to wear out. At some point, they won’t be usable anymore and have to be skipped.
Because it is memory-based, random access is theoretically as fast as sequential access. So, you don’t need to keep the fragments of your files together. It makes it possible to do wear-leveling and thus, “increase” the lifetime of the chip.
A simple way of doing wear-leveling is to keep track of the number of times a block has been erased and use the block that has been the least erased when updating data.
All these constraints make it hard to write a flash filesystem.
UBI intends to deal with all MTD-specific operations while still presenting random-access volumes to the the upper-layer. The first – and as for now, only – implementation using UBI is UBIFS. UBI is a “volume manager” and maps physical erase blocks (PEB) to logical erase blocks (LEB). The LEBs are smaller than the PEBs because of meta-data and headers.
How to use UBI on my board ?
There are mainly 2 ways to do that:
On a booted Linux system, approximately the same way you would create a partition on your desktop’s hard drive ;
From the bootloader, by flashing a previously prepared UBI image ;
Whatever solution you choose, you need to know the sizes of:
the eraseblocks (PEB) ;
the pages (or “minimum input/output size”) ;
the subpages (it may be the same as the min i/o size) ;
From these details, you can deduce another one: the size of logical erase blocks. It is the size of the PEB minus a data offset which is:
(subpage+page truncated to page size). This formula makes some assumption but should be correct if the subpage size is more than 8B and the page size more than 64B (see the source for more information). The best way to be sure of this size is to use mtdinfo on linux on the board. mtdinfo is part of the ubi-utils (part of mtd-utils). It’s probably available in your build system.
In both cases, you will also need a UBIFS image. In the way of JFFS2, mkfs.ubifs comes in mtd-utils (thus, you also need them on your desktop. Warning: mtd-utils in Ubuntu 10.10 are reported to be buggy ; if you use this distribution, recompile them from their git tree). Here is an example of how you can invoke it:
I think it’s the best method to understand how UBI is structured.
You first need to enable UBI and UBIFS in the kernel and install the mtd-utils package (for Debian and Ubuntu) on your box. You may also compile mtd-utils from its sources.
Once you have your UBIFS image at hand, let’s sing the UBI song:
Let’s examine each command. ubiformat erases an MTD partition but keeps its erase counters ((‘X’ is the number of the partition you want to use). ubiattach creates a UBI device from the MTD partition. This UBI device is then referred to by UBI as ubi0 (if it is the first device). ubimkvol creates a volume on a UBI device ; this volume is referred to as ubi0_0 (if it is the first volume on the device). ubiupdatevol puts an image on an empty volume. (use ubiupdatevol -t /dev/ubi0_0 to empty a volume). At last, the well-known mount can be invoked using <device>:<volume>
Solution B – Prepare a UBI image ready to be flashed
It is more common to directly flash filesystem images directly from the bootloader. It is made possible by ubinize to prepare a UBI device image containing one or more volumes.
ubinize reads a configuration file (in the very simple INI format) describing the volumes and their configuration. Here is an example of a device with two volumes ; one, named rootfs is read-only (static), the other one, data is read-write (dynamic) ; the autoresize flag makes UBI resize to volume to use the whole unused space at initialization. The name of the sections is totally arbitrary.
For instance, with the previous examples and assuming the UBI device has been created/flashed on /dev/mtd1:
ubi.mtd=1 root=ubi0:rootfs rootfstype=ubifs
Conclusion
Creating and using a UBIFS filesystem is not as easy as with JFFS2 but UBI/UBIFS is designed to be more robust and UBI will ease the development of new filesystems. The authors of UBI have pointed some memory usage scalability problems but if a second version of UBI were written, filesystems on top of it would not need to be modified.
Troubleshooting
In case your system is missing the /dev/ubi_ctrl, /dev/ubi0 or /dev/ubi0_X device files, we advise you to recompile your kernel with DEVTMPFS and DEVTMPFS_MOUNT. This way, all the devices existing on your system will appear in /dev.
If you get write errors (code -74 or -5, probably), check that CONFIG_MTD_NAND_VERIFY_WRITE (respectively, ONENAND) is disabled : verifying subpages writes isn’t supported yet.
Sources
The primary place for information about MTD support in Linux is infradead.org. There also is a mailing list which you can also subscribe to.
The kernel sources under drivers/mtd and fs/ubisfs are also very helpful.
Reducing start-up time looks like one of the most discussed topics nowadays, for both embedded and desktop systems. Typically, the boot process consists of three steps:
First-stage bootloader
Second-stage bootloader
Linux kernel
The first-stage bootloader is often a tiny piece of code whose sole purpose is to bring the hardware in a state where it is able to execute more elaborate programs. On our testing board (CALAO TNY-A9260), it’s a piece of code the CPU stores in internal SRAM and its size is limited to 4Kib, which is a very small amount of space indeed. The second-stage bootloader often provides more advanced features, like downloading the kernel from the network, looking at the contents of the memory, and so on. On our board, this second-stage bootloader is the famous U-Boot.
One way of achieving a faster boot is to simply bypass the second-stage bootloader, and directly boot Linux from the first-stage bootloader. This first-stage bootloader here is AT91bootstrap, which is an open-source bootloader developed by Atmel for their AT91 ARM-based SoCs. While this approach is somewhat static, it’s suitable for production use when the needs are simple (like simply loading a kernel from NAND flash and booting it), and allows to effectively reduce the boot time by not loading U-Boot at all. On our testing board, that saves about 2s.
As we have the source, it’s rather easy to modify AT91bootstrap to suit our needs. To make things easier, we’ll boot using an existing U-Boot uImage. The only requirement is that it should be an uncompressed uImage, like the one automatically generated by make uImage when building the kernel (there’s not much point using such compressed uImage files on ARM anyway, as it is possible to build self-extractible compressed kernels on this platform).
Looking at the (shortened) main.c, the code that actually boots the kernel looks like this:
int main(void)
{
/* ================== 1st step: Hardware Initialization ================= */
/* Performs the hardware initialization */
hw_init();
/* Load from Nandflash in RAM */
load_nandflash(IMG_ADDRESS, IMG_SIZE, JUMP_ADDR);
/* Jump to the Image Address */
return JUMP_ADDR;
}
In the original source code, load_nandflash actually loads the second-stage bootloader, and then jumps directly to JUMP_ADDR (this value can be found in U-Boot as TEXT_BASE, in the board-specific file config.mk. This is the base address from which the program will be executed). Now, if we want to load the kernel directly instead of a second-level bootloader, we need to know a handful of values:
the kernel image address (we will reuse IMG_ADDRESS here, but one could
imagine reading the actual image address from a fixed location in NAND)
the kernel size
the kernel load address
the kernel entry point
The last three values can be extracted from the uImage header. We will not hard-code the kernel size as it was previously the case (using IMG_SIZE), as this would lead to set a maximum size for the image and would force us to copy more data than necessary. All those values are stored as 32 bits bigendian in the header. Looking at the struct image_header declaration from image.h in the uboot-mkimage sources, we can see that the header structure is like this:
typedef struct image_header {
uint32_t ih_magic; /* Image Header Magic Number */
uint32_t ih_hcrc; /* Image Header CRC Checksum */
uint32_t ih_time; /* Image Creation Timestamp */
uint32_t ih_size; /* Image Data Size */
uint32_t ih_load; /* Data Load Address */
uint32_t ih_ep; /* Entry Point Address */
uint32_t ih_dcrc; /* Image Data CRC Checksum */
uint8_t ih_os; /* Operating System */
uint8_t ih_arch; /* CPU architecture */
uint8_t ih_type; /* Image Type */
uint8_t ih_comp; /* Compression Type */
uint8_t ih_name[IH_NMLEN]; /* Image Name */
} image_header_t;
It’s quite easy to determine where the values we’re looking for actually are in the uImage header.
ih_size is the fourth member, hence we can find it at offset 12
ih_load and ih_ep are right after ih_size, and therefore can be found at offset 16 and 20.
A first call to load_nandflash is necessary to get those values. As the data we need are contained within the first 32 bytes, that’s all we need to load at first. However, some space is required in memory to actually store the data. The first-stage bootloader is running in internal SRAM, so we can pick any location we want in SDRAM. For the sake of simplicity, we’ll choose PHYS_SDRAM_BASEhere, which we define to the base address of the on-board SDRAM in the CPU address space. Then, a second call will be necessary to load the entire kernel image at the right load address.
Then all we need to do is:
#define be32_to_cpu(a) ((a)[0] << 24 | (a)[1] << 16 | (a)[2] << 8 | (a)[3])
#define PHYS_SDRAM_BASE 0x20000000
int main(void)
{
unsigned char *tmp;
unsigned long jump_addr;
unsigned long load_addr;
unsigned long size;
hw_init();
load_nandflash(IMG_ADDRESS, 0x20, PHYS_SDRAM_BASE);
/* Setup tmp so that we can read the kernel size */
tmp = PHYS_SDRAM_BASE + 12;
size = be32_to_cpu(tmp);
/* Now, load address */
tmp += 4;
load_addr = be32_to_cpu(tmp);
/* And finally, entry point */
tmp += 4;
jump_addr = be32_to_cpu(tmp);
/* Load the actual kernel */
load_nandflash(IMG_ADDRESS, size, load_addr - 0x40);
return jump_addr;
}
Note that the second call to load_nandflash could in theory be replaced by:
However, this will not work. What happens is that load_nandflash starts reading at an address aligned on a page boundary, so even when passing IMG_ADDRESS+0x40 as a first argument, reading will start at IMG_ADDRESS, leading to a failure (writes have to aligned on a page boundary, so it is safe to assume that IMG_ADDRESS is actually correctly aligned).
The above piece of code will silently fail if anything goes wrong, and does no checking at all – indeed, the binary size is very limited and we can’t afford to put more code than what is strictly necessary to boot the kernel.
Reviewing new possibilities for flash filesystems – My slides at ELCE 2008
With the release of Linux 2.6.27, including the new UBIFS filesystem for MTD storage, embedded Linux system developers now have multiple choices for their flash storage devices. As far as it is concerned, JFFS2 has also been improved and now has support for LZO compression, which makes uncompressing faster. So, how to choose between JFFS2, YAFFS2, and UBIFS?
To help our customers and the community make the right decision, I measured how these filesystems compare in terms of mount time, access time, read and write speed, as well as CPU usage in several corner cases and with different flash chip sizes.
I showed the results during the Embedded Linux Conference Europe event. Besides sharing lessons learned from these experiments, my presentation also introduced each filesystem and its implementation. I also gave advice for flash based block storage (such as Compact Flash and Solid State disks), to reduce the number of writes and avoid damaging flash blocks.
The main finding is that UBIFS outperforms both JFFS2 and YAFFS2 in almost all corner cases. As shown by the benchmarks, it has consistently good mount time, and read/write performance. If your products are using a recent kernel, and are still based on JFFS2, you should definitely try UBIFS and get significant performance benefits, in particular for boot time, as mounting a JFFS2 root filesystem can take several seconds!
The advent of UBIFS also questions the relevance of YAFFS2. YAFFS2 used to be a good alternative to JFFS2, but unlike UBIFS, it doesn’t support compression. Then, why choose YAFFS2, when a apparently superior alternative is available?
The only case in which JFFS2 can still make sense if when you have very small partitions, sizing just a few megabytes. In this case, the overhead from UBI, the erase-block management layer below UBIFS, is no longer negligible. You will be able to pack much less data than with JFFS2. In this case, you can still improve JFFS2’s performance by using some of its new features (more details in the presentation).
SquashFS is also another great alternative, as shown by my benchmarks. It’s true it is a block filesystem, but since it is read-only, and there is no problem to use it on a write-once mtdblock device. You should really consider it for the read-only parts in your system, though it is advisable to use it on top of UBI, to make its blocks participate to wear-leveling and bad block management. Again, you will find more details in my presentation.
The presentation also mentions LogFS, which is also a promising filesystem for flash storage. Unfortunately, LogFS is not available yet for recent kernels. Stay tuned and I will benchmark it as soon this situation changes.

 Flash storage, also called solid state, has multiple advantages over rotating storage. First, the absence of mechanical and moving parts eliminate noise, increase reliability and resistance to shock and vibrations, and also reduces heat dissipation as well as power consumption. Second, random access to data is also much faster, as you no longer have to move a disk head to the right location on the medium, which can take milliseconds.
Flash storage, also called solid state, has multiple advantages over rotating storage. First, the absence of mechanical and moving parts eliminate noise, increase reliability and resistance to shock and vibrations, and also reduces heat dissipation as well as power consumption. Second, random access to data is also much faster, as you no longer have to move a disk head to the right location on the medium, which can take milliseconds. 




