We’ve started to use Mastodon (in addition to Twitter and LinkedIn) to share quick news with you: new blog posts, contributions to Free Software projects, photos at events, etc.
Did you know Mastodon? I’ll like Twitter, but better, decentralized and really free (as in Free Software). I discovered it by attending one of the conferences we sponsor (Capitole du Libre in Toulouse, France) and by following the efforts of Framasoft to provide decentralized Internet services.
Being Free Software and not biased by the need to maximize revenue for its investors
It’s decentralized and therefore controlled by its users. You are free to join an instance that matches your interests and sensibility, but of course you can follow anyone on any other instance. It’s also easy to move to another instance or even host your own one
There are no Retweets but Boosts. Retweets allow to share a post with your own comments to all your followers. This creates flame wars in the best interest of Twitter. Twitter needs its users to spend as much time as possible viewing the content they host (and therefore their promoted content at the same time). Instead, Mastodon only allows to “boost” the visibility of someone else’s post, without allow you to add your own comments. Mastodon has no interest in making you stay as long as possible by creating flame wars. It just lets you focus on the content your are interested in.
In a nutshell, using Mastodon contributes to a better world in which users are in control of their data, interests and time.
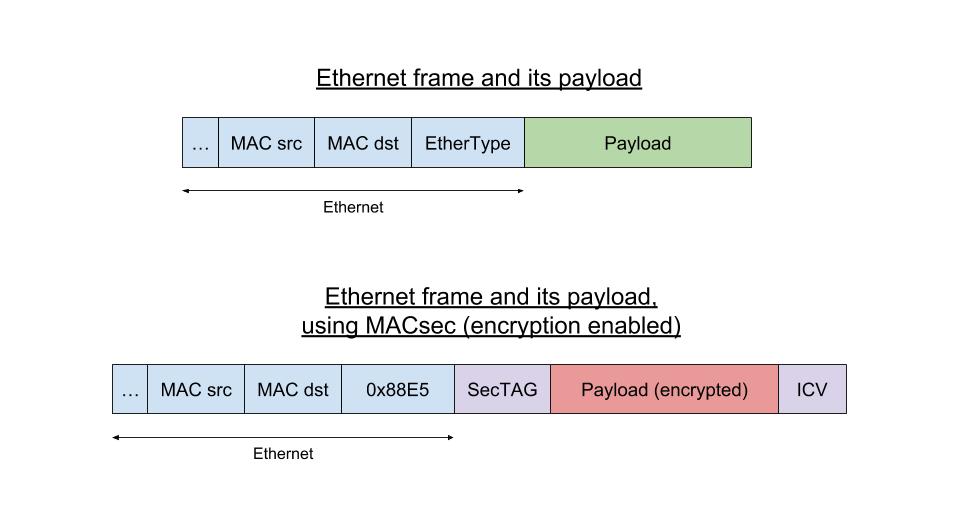
MACsec is an IEEE standard (IEEE 802.1AE) for MAC security, introduced in 2006. It defines a way to establish a protocol independent connection between two hosts with data confidentiality, authenticity and/or integrity, using GCM-AES-128. MACsec operates on the Ethernet layer and as such is a layer 2 protocol, which means it’s designed to secure traffic within a layer 2 network, including DHCP or ARP requests. It does not compete with other security solutions such as IPsec (layer 3) or TLS (layer 4), as all those solutions are used for their own specific use cases.
MACsec uses its own frame format with its own EtherType (a 2-bytes field found in Ethernet frames to indicate what the protocol encapsulated in the payload is). As an example, when encapsulating an IPv4 frame, we would have Ethernet<MACsec<IPv4 instead of Ethernet<IPv4.
The MACsec configuration within a node is represented at the top level by Secure Channels. A secure channel is identified by its SCI (Secure Channel Identifier) and contains parameters such as the encryption, protection and replay protection booleans. A secure channel is either a transmit or a receive one: the receive secure channel configuration on a given host should match the transmit one of another host for MACsec traffic to flow successfully.
Within each secure channel, security associations are described. They are identified by an association number and define the encryption/decryption keys used and the current packet number, which is used for replay protection.
MACsec support in Linux
Linux has a software implementation of MACsec, found at drivers/net/macsec.c, which was introduced by Red Hat engineer Sabrina Dubroca in 2016 and available since Linux 4.5. The support is implemented as full virtual network devices, on per transmit secure channel, attached to a parent network device. The parent interface only sees raw packets, which are in the MACsec case raw Ethernet packets with protected or encrypted content. This design is very similar to other supported protocols in Linux such as VLANs.
MACsec support was also introduced in iproute2, a collection of utilities aiming at configuring various networking parts of the kernel (interfaces management, IP configuration, routes…). The command to use is ip macsec.
If we were to configure a secure channel between two hosts we would first need to create a virtual MACsec interface (representing a transmit secure channel) on both hosts, on top of a physical network interface. Let’s say we use eth0 on both our hosts (Alice and Bob), and we want to encrypt the MACsec traffic:
Alice # ip macsec add link eth0 macsec0 type macsec encrypt on
Bob # ip macsec add link eth0 macsec0 type macsec encrypt on
The next step would be to configure matching receiving secure channel on both hosts:
Alice # ip macsec add macsec0 rx port 1 address <Bob's eth0 MAC>
Bob # ip macsec add macsec0 rx port 1 address <Alice's eth0 MAC>
We would then configure the transmit channels, and for each we would need to generate a key:
Alice # hexdump -n 16 -e '4/4 "%08x" 1 "\n"' /dev/random
d29a43c8cba96a325f6b6a40a214c58c
Alice # ip macsec add macsec0 tx sa 0 pn 1 \
on key d29a43c8cba96a325f6b6a40a214c58c
Bob # hexdump -n 16 -e '4/4 "%08x" 1 "\n"' /dev/random
a1e15a1d91222196fde87b2d75a4fac0
Bob # ip macsec add macsec0 tx sa 0 pn 1 \
on key a1e15a1d91222196fde87b2d75a4fac0
We finally need to configure the receive channels, so that the hosts can authenticate and decrypt packets:
Alice # ip macsec add macsec0 rx port 1 \
address <Bob's MAC> sa 0 pn 1 \
on key 00 a1e15a1d91222196fde87b2d75a4fac0
Bob # ip macsec add macsec0 rx port 1 \
address <Alice's MAC> sa 0 pn 1 \
on key 00 d29a43c8cba96a325f6b6a40a214c58c
Once all of the MACsec configuration is done we would be able to exchange traffic between Alice and Bob, using authenticated and encrypted packets:
Alice # ip link set macsec0 up
Alice # ip addr add 192.168.42.1/24 dev macsec0
Bob # ip link set macsec0 up
Bob # ip addr add 192.168.42.2/24 dev macsec0
What’s coming next: hardware offloading
There are hardware devices featuring a MACsec transformation implementation which can be used to offload the frame generation and encryption / authentication of MACsec frames (for both ingress and egress frames). The benefit of hardware offloading is to discharge the CPU from doing certain operations (in our case MACsec transformations) by doing them in a dedicated hardware engine, which may or may not provide better performance. The idea is essentially to free the CPU from being used by a single application so that the system in its whole runs better.
MACsec offloading devices aren’t currently supported in the Linux kernel and no generic infrastructure is available to delegate MACsec operation to a given hardware device. At Bootlin over the last months we worked on adding such an infrastructure and support for offloading MACsec operations to a first device.
This work was done in two steps. First we needed to extend the current MACsec implementation to propagate commands and configuration to hardware drivers. Our idea was to leverage the current MACsec software implementation to use the exact same commands described above to setup an hardware accelerated MACsec connection, when a Linux networking port supports it. This should allow to have a more maintainable implementation as well.
We then worked on implementing a MACsec specific helper in a networking PHY driver : the Microsemi VSC8584 Ethernet PHY. This PHY has a MACsec engine which can be used to match flows and to perform MACsec transformations and operations. When configured packets can be encrypted and decrypted, protected and validated, without the CPU intervention.
Conclusion
We recently sent a first version of patch series to the Linux network mailing list, which is currently being discussed. This series of patches introduces both the hardware offloading support for MACsec and the ability to offload MACsec operations to a first hardware engine. We hope support for other MACsec engines will come after!
BeagleBoneBlack Wireless board booting through tftp and NFS
Here are details about booting the Beagle Bone Black Wireless board through NFS. I’m writing this here because it doesn’t seem to be documented anywhere else (except in our Linux kernel and driver development course, for which I had to support this feature).
Why
Booting a board on a root filesystem that is a directory on your workstation (development PC) or on a server, shared through the network, is very convenient for development purposes.
For example, you can update kernel modules or programs by recompiling them on your PC, and the target board will immediately “see” the updates. There’s no need to transfer them in some way.
Doing this is quite straightforward on boards that have an Ethernet port, and well documented throughout the Internet (see our instructions). However, things get more complicated with boards that have no such port, such as the Beagle Bone Black Wireless or the Pocket Beagle.
The Beagle Bone Black Wireless board has WiFi support, but booting on NFS directly from the kernel (instead of using an initramfs) is another kind of challenge.
Something easier to use is networking over USB device (also called USB gadget as our operating system is running on the USB device side), which is supported by both Linux and U-Boot.
Note that the below instructions also work on the original Beagle Bone Black, bringing the convenience of not having to use an RJ45 cable. All you need is the USB device cable that you’re using for power supply too.
These instructions should also support the Pocket Beagle board, which is similar, though much simpler.
Preparing U-Boot
This part may just work out of the box if the U-Boot version on your board is recent and was built using the default configuration for your board.
If that’s not the case, you can reflash U-Boot on your board using our instructions.
These instructions have been tested on Ubuntu 18.04, but they should be easy to adapt on other GNU/Linux distributions.
To configure your network interface on the workstation side, we need to know the name of the network interface connected to your board.
However, you won’t be able to see the network interface corresponding to the Ethernet over USB device connection yet, because it’s only active when the board turns it on, from U-Boot or from Linux. When this happens, the network interface name will be enx. Given the value we gave to usbnet_hostaddr, it will therefore be enxf8dc7a000001.
Then, instead of configuring the host IP address from NetWork Manager’s graphical interface, let’s do it through its command line interface, which is so much easier to use:
nmcli con add type ethernet ifname enxf8dc7a000001 ip4 192.168.0.1/24
To download the kernel and device tree blob which are also on your PC, let’s install a TFTP server on it:
sudo apt install tftpd-hpa
You can then test the TFTP connection, which is also a way to test that USB networking works. First, put a small text file in /var/lib/tftpboot.
Then, from U-Boot, do:
tftp 0x81000000 textfile.txt
The tftp command should have downloaded the textfile.txt file from your development workstation into the board’s RAM at location 0x81000000. You can verify that the download was successful by dumping the contents of memory:
md 0x81000000
We are now ready to load and boot a Linux kernel!
Kernel configuration
These instructions were tested with Linux 4.19
Configuring and cross-compiling the Linux kernel for the board is outside the scope of this article, but again, such information is easy to find (such as in our training slides).
Here, we’re just sharing the Linux kernel configuration settings that are needed for networking over USB device. Since they are not supported by the default configuration file for the omap2plus CPU family (for several reasons that were discussed on the Linux kernel mainling list), it took a bit of time to figure out which ones were needed. Here they are:
Add the below options to support networking over USB device:
CONFIG_USB_GADGET=y
CONFIG_USB_MUSB_HDRC=y: Driver for the USB OTG controller
CONFIG_USB_MUSB_GADGET=y: Use the USB OTG controller in device (gadget) mode
CONFIG_USB_MUSB_DSPS=y
Check the dependencies of CONFIG_AM335X_PHY_USB. You need to set CONFIG_NOP_USB_XCEIV=y to be able to set CONFIG_AM335X_PHY_USB=y
Find the ”USB Gadget precomposed configurations” menu and set it to static instead of module so that CONFIG_USB_ETH=y
How did I found out which settings were needed? I had to check the device tree to find the USB device controller. Then, using git grep, I found the driver that was supporting the corresponding compatible string. Then, looking at the Makefile in the driver directory, I found which kernel configuration settings were needed.
When compiling is over, copy the zImage and am335x-boneblack-wireless.dtb files to the TFTP server home directory (/var/lib/tftpboot).
You also need an NFS server on your workstation:
sudo apt install nfs-kernel-server
Then edit the /etc/exports file as root to add the following line, assuming that the IP address of your board will be 192.168.0.100:
Now check the kernel log and make sure an IP address is correctly assigned to your board by Linux. If NFS booting doesn’t work yet, that could be because of NFS server or client issues. If that’s the case, you should find details in the NFS server logs in /var/log/syslog on your PC.
First of all, the entire team at Bootlin wishes you a Happy New Year, and best wishes for 2019 in your personal and professional life. The beginning of the new year is a good time to look back and see the achievements of the past year, which is why we review the 2018 year in terms of Bootlin news and activity:
Due to a legal battle related to trademarks, we decided to change our name to Bootlin at the beginning of 2018. The company was not sold or purchased, it is still owned by the same people, and driven by the same team of engineers. This change of name obviously took a lot of time, which could have been used for other more productive contribution activities, but it’s finally done, and in 2019 we can move on and leave this legal battle behind us. See our blog post for more details.
Kernel contributions
In 2018, we contributed to the 4.15, 4.16, 4.17, 4.18, 4.19 and 4.20 kernel releases a total of 1365 commits, putting Bootlin regularly in the top 20 companies contributing to the Linux kernel.
Our most significant contributions have been:
Thanks to a successful crowdfunding campaign launched in February, we have been able to dedicate enough time to develop and upstream a Linux kernel driver and associated user-space library to support hardware-accelerated video decoding on Allwinner processors. This was a massive effort as it required discussing with the Linux kernel community a new set of userspace interfaces to support stateless video decoders. The base of our driver was merged in Linux 4.20 and supports only MPEG2 decoding. Support for H264 and H265 decoding is ready and has been posted several times, but discussions on the userspace interface are still on-going. See our numerous blog posts and especially the end of year status.
We have developed and contributed a brand new Linux kernel subsystem to support the MIPI I3C bus, a modern bus offering an alternative to SPI or I2C. Being vastly different from I2C, it required a completely separate subsystem located in drivers/i3c/. Along with the core subsystem itself, we developed a driver for the Cadence I3C master, and a driver for a Cadence I3C GPIO expander. See our blog posts on I3C for more details.
We contributed a new interface called exec_op for NAND flash controller drivers, which allows the MTD subsystem to more easily support optimized NAND flash controllers and vendor-specific NAND commands. This new interface was originally developed for the Marvell NAND controller driver, but a number of other drivers have been converted since then, and all new drivers make use of his interface. See our blog post for more details.
We contributed support for the Microsemi VSC7513 and VSC7514 MIPS processors, with the base support (irqchip, pinctrl, gpio, reset, DT) but more importantly a massive switchdev driver to support the major feature of these processors: a built-in gigabit Ethernet switch. Our switchdev driver supports bridging, STP, IGMP snooping, VLAN filtering and link aggregation. See our blog posts about platform support and switchdev support.
We contributed a new subsystem called spi-mem, which allows to support SPI flash memories in a generic way, re-using SPI controller drivers for regular SPI devices, SPI NOR flashes and SPI NAND flashes, instead of having separate controller drivers as was done until now for SPI NOR support. On top of spi-mem, we added support for SPI NAND flash memories to Linux. See our blog post on spi-mem: bringing some consistency to the SPI memory ecosystem.
We continued to work on improving the support for Marvell ARM processors
Improvements in the inside-secure crypto accelerator driver: support for new crypto algorithms, support for the EIP97 variant which enabled using the driver on Armada 37xx in addition to the already support EIP197 variant used on Armada 7K/8K, numerous fixes and performance improvements
Improvements in the mvpp2 network controller driver, used on Armada 7K/8K: RSS support, support for SFP ports, HW offloading for VLAN filtering, 1000baseX and 2500baseX support
On Armada 7K/8K, we added support for the NAND controller and the thermal sensors.
On Armada 37xx, we added cpufreq support and the first pieces of suspend/resume support.
Allwinner platform support improvements: of course the Allwinner VPU driver detailed above, but also general improvements to the Allwinner A83 support (for which we delivered a complete BSP for a customer), improvements to the sun4i display driver (especially support for YUV planes, and MIPI DSI support on Allwinner A33), improvements to the sun8i-codec audio driver, and improvements to the AXP209 and AXP813 PMIC drivers.
For Microchip/Atmel platforms, we continued our maintenance work, with a focus this year on reworking the representation of the platform clocks in the Device Tree.
U-Boot contributions
Even if Bootlin is mainly active as a Linux kernel contributor, we also contribute to U-Boot, and we have been more active in 2018 than we were in the past. In a recent blog post, we summarized our most significant contributions:
Support for SPI NAND memories, as well as a significant sync of the MTD stack in U-Boot with the one from Linux, and the introduction of a generic mtd U-Boot command to manipulate all types of flash memories
Generic support for TPMv2 and for TPMv2 chips connected over SPI
Brand new subsystem to support 1-wire controllers and devices
Support for the Microsemi Ocelot and Luton MIPS processors. We also contributed support for Microsemi Ocelot to Linux, as discussed above
Support for the ARM PL022 SPI controller
Support for multiple U-Boot environment backends
Support for Microsemi VSC8574 and VSC8584 Ethernet PHYs
In total, we contributed 172 commits to U-Boot in 2018.
Other contributions
Beyond Linux and U-Boot, we also contributed to a few other open-source projects:
We contributed to the Intel GPU Tools project, adding support for testing more pixel formats, to test the display pipeline of the RaspberryPi, in combination with the Chamelium testing hardware. See our blog post and intel-gpu-tools commits
We made our Elixir Cross Referencer project easier to customize, so that contributors can add support for a new source code repository through a single plugin file, instead of having to modify the main source files. Thanks to this, we currently index 8 projects on https://elixir.bootlin.com/.
Other engineering projects
While many of our engineering projects are directly related to upstream contributions, which have been described above, some are not always leading to direct contributions. Here is a small selection of other interesting projects we worked on in 2018:
For a German customer in the healthcare industry, wrote a complete U-Boot, Linux and Buildroot BSP for a custom NXP i.MX6 platform.
For an international company in the TV/set-top box industry, worked on adding support for top-level parallel build to Buildroot.
For a Netherlands based customer in the gaming industry, wrote a complete U-Boot, Linux and Buildrot BSP for a custom Allwinner A33 platform, with significant boot time optimization to quickly boot up to a Qt5 OpenGL application.
For a Spanish customer, brought up a PCM1789 audio codec connected to a NXP i.MX6 processor, and for an Italian customer, brought up a CS4272 audio codec connected to an Allwinner A20 processor. Under Linux, of course!
We continued working for a major US customer, delivering an i.MX6 and SPEAr600 Linux BSP based on Yocto. Our work in 2018 was mainly focused on supporting secure boot on i.MX6 (see our talk at ELC on this topic) and porting a modern version of U-Boot on the SPEAr600 platform.
We have continued to maintain toolchains.bootlin.com, by keeping the toolchains reguarly updated, and adding support for the RISC-V 64 bit architecture. See ourblogposts.
Conferences
In 2018, Bootlin was at a large number of conferences and events:
A large part of the team attended the Embedded Linux Conference Europe, where we gave three talks (support for stateless video codecs in Linux, networking from the MAC to the link partner, SPI memory support in U-Boot and Linux), 2 tutorials (introduction to kernel driver development, introduction to Buildroot) and 2 demonstrations (Allwinner VPU work, and switchdev driver for Microsemi platforms). See our report from the event and our selection of talks from other speakers.
Right next to the Embedded Linux Conference Europe, Maxime Ripard attended the Media Summit to discuss the V4L Linux subsystem, see his report, while Maxime Chevallier attended the Real-Time Summit, see his report.
In 2018, we gave our Embedded Linux, Linux kernel, Yocto Project and Buildroot training courses on-site in the United States, Portugal, Belgium, Germany, France, Spain, Serbia, Greece, Bosnia, Finland and Switzerland. As you can see, we travel all around the world to teach our training courses.
Of course, we continued our public training sessions organized in Avignon (France), given in English by Bootlin founder and CEO Michael Opdenacker.
In 2018, we made 217 commits to our training materials Git repository, showing our continuous work to keep them updated. Our training materials remain all freely available under a Creative Commons CC-BY-SA license, as they have been since Bootlin creation fifteen years ago.
Office expansion
In 2018, we expanded both our Toulouse and Lyon offices:
We moved our office in Toulouse mid-2018 from a 100m² surface to a 180m² one, offering more room for the existing team, and room to expand the team in the coming years. As of January 1, 2019, we have a team of 8 engineers working in Toulouse.
We moved our office in Lyon end of 2018 from a small one room office of 30m² to a full office of 100m², here as well to expand the team in the coming years. As of January 1, 2019, the team in Lyon has 2 engineers, but we hope to increase this number soon (see Recruiting below).
Recruiting
In terms of recruiting:
Maxime Chevallier joined us in February 2018, and has since then been mostly working on networking topics on Marvell platforms, but also a few other engineering projects.
Paul Kocialkowski joined us in March 2018 for an internship focused on the Allwinner VPU development and then was hired as a full-time engineer starting November 2018.
Thanks to our office expansion in Lyon, we have an open position for a Embedded Linux and Kernel engineer with existing experience in Lyon. See our blog post (in French) for more details.
We have openings for several internships in 2019, on Linux, U-Boot, Buildroot and Elixir related topics. See our blog post (in French).
Financial support
In 2018, we continued to support organizations and events who promote and defend Free Software:
Donating 1,024 EUR to Framasoft, an organization whose goal (in addition to supporting Free Software) is to decentralize Internet services. For example, they made a huge effort to release PeerTube in 2018, a peer-to-peer and of course Free Software alternative to centralized video hosting solutions.
Donating 1,024 EUR to Wikimedia France, to support free knowledge sharing through projects such as Wikipedia and Wikimedia Commons.
Donating 1,024 EUR to April, a French organization doing terrific work to promote Free Software, to follow the evolution of national and European law, and to animate campaigns to keep our political representatives aware of the needs of Free Software developers and users.
We have plenty of ideas for 2019, so stay tuned for more news. We hope that 2019 will be a great year for you too, with many contributions of all kinds to the lives of others.
We regularly post about Bootlin contributions to the Linux kernel, but we more rarely post about our U-Boot contributions. Even though we are a bit less active in U-Boot than we are in Linux, we do quite a bit of upstream U-Boot work as well. In this blog post, we do a review of our most significant U-Boot contributions in 2018.
U-Boot 2018.03
Maxime Ripard contributed support for using multiple U-Boot environments. Thanks to this, multiple U-Boot environment backends can be compiled into a single U-Boot binary, so that it can support falling back to a different environment backend if needed. For example, U-Boot can try to load an environment from a file in a FAT partition, and if that fails, try to load from raw MMC storage. As explained by Maxime Ripard in his cover letter, this is useful to help converting Allwinner-based platforms from an environment stored in raw MMC to an environment stored in a FAT partition.
U-Boot 2018.05
Miquèl Raynal contributed support for the Allwinner A33 based Nintendo NES Classic platform. It was also the first Allwinner A33 platform supported in U-Boot that boots from NAND, so as part of this work, Miquèl had to change the Allwinner NAND driver used in the SPL to make it work on Allwinner A31, which required using PIO transfers instead of DMA, and a number of other changes.
U-Boot 2018.07
Miquèl Raynal contributed generic support for TPMv2, and also specifically support for TPMv2 chips over SPI. We will publish a more detailed blog post about this topic in the near future.
U-Boot 2018.09
Quentin Schulz improved the env import command so that it can filter the environment variables it loads from the provided environment. This allows to white-list only a few selected environment variables in cases where the system is locked down by secure boot, but we still need a small writable U-Boot environment to store a few variables. As part of this release, Miquèl Raynal also contributed a few TPM-related fixes.
U-Boot 2018.11
Miquèl Raynal contributed a lot of changes in the MTD subsystem, which brought support for SPI NAND flash memories in U-Boot. We described this work in a previous blog post. Boris Brezillon helped by submitting a number of fixes related to this effort.
Miquèl Raynal contributed a new mtd command, which can be used in a generic way to access all flash memories. This command will replace commands such as sf, nand, etc. We will publish in the near future a separate blog post about this topic.
Quentin Schulz contributed a SPI controller driver for the ARM PL022 SPI controller, which we are using on an old STMicro SPEAr600 platform.
Maxime Ripard contributed a brand new subsystem to support One Wire devices. This work was initially started by Maxime years ago as part of our work on the CHIP platform from Nextthing, and was picked up by Eugen Hristev from Microchip who pushed it all the way to upstream U-Boot.
U-Boot 2019.01
Grégory Clement contributed the support for the Microchip/Microsemi Ocelot and Luton MIPS platforms, which includes the core code, but also a GPIO driver and a pinctrl driver.
Boris Brezillon contributed a number of fixes in the MTD subsystem to address various issues introduced by our work on this subsystem in the previous release.
Quentin Schulz contributed support for the VSC8574 and VSC8584 Ethernet PHYs from Microchip/Microsemi.
Miquèl Raynal improved the NAND controller driver for Marvell platforms by adding raw read support, which was used to add support for NAND chips using 2 KB pages and a ECC strength of 8 bits.
Overall contribution statistics
Overall, during this year, Bootlin engineer Miquèl Raynal contributed 90 commits, Maxime Ripard 33 commits, Boris Brezillon 24 commits, Quentin Schulz 14 commits, Grégory Clement 9 commits and Mylène Josserand 2 commits, a total of 172 commits, including some significant new features: SPI NAND support, TPMv2 support, One Wire subsystem, Ocelot and Luton platform support, ARM PL022 SPI controller support, support for additional Ethernet PHY, support for multiple environments.
We expect to continue our involvement in upstream U-Boot development, starting with a new network driver for the Microchip/Microsemi Ocelot and Luton platforms.
The end of 2018 is approaching, which is the right time to provide an update on where we stand with the Allwinner VPU support in Linux. The promise of our Kickstarter campaign was to deliver all funded stretch goals by the end of 2018. As we’ll explain below, all the goals have been met, and only the upstreaming process is not completely finished for some features.
With the Linux 4.20 release happening just a few days ago, the core of the Cedrus driver and the media Requests API that supports it are finally available through Linus Torvalds’ tree! They provide the required interface for hardware-accelerated MPEG-2 decoding on the A13, A20, A33 and H3 Allwinner SoCs.
Cedrus driver in staging
Discussions regarding the details of the stateless video decoding interface offered by the V4L2 API are still taking place, which explains why our driver was integrated as a staging media driver. It was also decided to hide the associated interface for MPEG-2 decoding from the public kernel headers for now. This way, the interface is not considered stable and can keep evolving as discussions are still taking place. Because the kernel has a policy of never breaking backward compatibility, these interfaces will hardly evolve once they are declared stable, so it is crucial to ensure they are ready when that happens. This is especially true given the level of complexity associated with video decoding and the various pitfalls paving that road.
Status of H264 and H265 decoding support
The code for H264 and H265 decoding is already developed and functional, has already been submitted for upstream inclusion but it hasn’t been merged yet. However, with the decoding interfaces considered unstable for now, it should become easier to bring-in H.264 and H.265 decoding support to mainline. Support for these two codecs in the API and our driver is still under review and we will continue sending new iterations for them, with the suggested changes and fixes as well as adaptations for the still-evolving decoding interface. More specifically, our series need to be updated to the latest proposal for identifying reference frames, which is now based on the timestamps of the buffers.
Platform support: H5, A64 and A10 on the horizon
Regarding the platforms supported by our driver, the patches for H5 and A64 support were accepted since our last update and they will make it to Linux 4.21! We are also looking to send out support for the A10, which was missing from our previous series (but shouldn’t cause any particular trouble).
DRM driver improvements
The adaptations for the DRM driver allowing to display the raw decoded frames from the VPU on older platforms were also finalized, with the first half of the series already queued for 4.21. Subsequent changes in the series are still waiting for more reviews as they affect common parts of the framework.
Conclusion
Overall, we are slowly closing down on this project and hoping to get the remaining pieces of our work integrated in mainline Linux as soon as possible, as there seems to be very few obstacles left in the way.
Drawing from Mylène Josserand, based on a picture from Samuel Blanc (https://commons.wikimedia.org/wiki/File:Manchot_royal_-_King_Penguin.jpg)The Linux 4.20 kernel has been released just before Christmas, on December 23. As usual, LWN had a very nice coverage of the most significant features and improvements provided by this new release as part of the merge window articles: part 1 and part 2.
Bootlin once again contributed to this Linux 4.20 release, with a total of 216 non-merge commits, which puts us the 13th contributing company by number of commits and the 8th contributing company by number of lines changed, according to LWN statistics for the 4.20 release.
Significant Bootlin contributions
For Linux 4.20, the most significant contributions from Bootlin have been:
On the support for Marvell platforms
Antoine Ténart reworked how the “software thread” mechanism is handled in the mvpp2 network driver, used on Marvell Armada 375 and 7K/8K.
Maxime Chevallier enabled XPS support in the same mvpp2 driver
Maxime Chevallier added logic to support 2.5G speed in the mvneta driver, but this logic is not enabled yet, as we don’t have the necessary COMPHY driver for Armada 38x to really allow using 2.5G speed.
Miquèl Raynal added suspend/resume support for the Armada 37xx clock driver. This is part of a larger work to enable suspend/resume on the Armada 37xx platform.
Miquèl Raynal improved the Marvell ICU driver to support SEI interrupts. The ICU is the Interrupt Collector Unit, found on Marvell Armada 7K/8K. It turns wired interrupts from a part of the chip called the “Communication Processor” (CP) into message interrupts so that they can be notified to the other part of the chip called the “Application Processor” (AP), which contains the CPU core and GIC.
Thomas Petazzoni introduced some common code in the PCI subsystem to emulate a PCI root port bridge, and converted the pci-mvebu and pci-aardvark drivers to use it. pci-mvebu already had such an emulation logic, but since it became also needed for pci-aardvark, we turn it into a piece of common code so that it can be shared by both drivers (and perhaps others in the future). pci-mvebu is used on Marvell Armada XP, 370, 375, 38x, while pci-aardvark is used on Marvell Armada 37xx.
On the support for Allwinner platforms
Paul Kocialkowski contributed the Cedrus VPU driver, with for now just MPEG2 decoding support. This work was done thanks to the successful crowd-funding campaign we did in February/March 2018.
Paul Kocialkowski contributed a few fixes to the sun4i DRM display driver.
On the support for Microchip/Microsemi MIPS platforms
Alexandre Belloni added support for the Microsemi Jaguar2 in the Designware SPI controller driver
Alexandre Belloni added support for the Microsemi Ocelot in the Designware I2C controller driver
Quentin Schulz contributed a new driver in the PHY subsystem to configure the SERDES muxing on Microsemi Ocelot platforms
Quentin Schulz contributed a new Device Tree description for the Microsemi Ocelot PCB120 platform
On the support Microchip/Atmel ARM platforms
Alexandre Belloni got the first step of the clock drivers rework merged. The purpose of this rework is to move from a Device Tree representation with one Device Tree node per clock to a much simpler representation with only one Device Tree node for the whole clock controller. The SAMA5D2, SAMA5D4, AT91SAM9260, AT91SAM9x5 at AT91SAM9RL clock drivers have already been converted. Other platforms and DT changes will arrive in future releases.
In the support for RaspberryPi platforms
Boris Brezillon contributed a few minor fixes for the vc4 DRM driver.
In the RTC subsystem
As the subsystem maintainer, Alexandre Belloni as usual did a number of cleanups and improvements in numerous drivers, especially to use more modern APIs where possible.
In the network subsystem
Quentin Schulz contributed extensive support for the Microsemi VSC8574 and VSC8584 Ethernet PHYs.
In the MTD subsystem
Subsystem maintainer Boris Brezillon did a lot of changes to pass a nand_chip object to numerous NAND subsystem hooks, and fixed all the drivers accordingly.
Boris Brezillon also deprecated a significant number of NAND subsystem hooks, by introducing a nand_legacy structure with legacy hooks. This should encourage developers to move their drivers to the more modern MTD/NAND APIs.
Bootlin maintainers activity
A number of Bootlin engineers are maintainers in the Linux kernel, so their work is not visible as patch authors, but rather as developers reviewing and merging patches contributed by others. As part of this maintainer work:
Maxime Ripard reviewed and merged 47 patches from other developers, as the Allwinner platform co-maintainer
Boris Brezillon reviewed and merged 36 patches from other developers, as the MTD subsystem co-maintainer
Alexandre Belloni reviewed and merged 64 patches from other developers, as the RTC subsystem maintainer and the Microchip/Atmel platform co-maintainer
Grégory Clement reviewed and merged 25 patches from other developers, as the Marvell platform co-maintainer
Miquèl Raynal reviewed and merged 71 patches from other developers, as the NAND subsystem co-maintainer
Back in August 2017, we wrote in a blog post about the first iteration of the Linux kernel subsystem we proposed to support the brand new MIPI I3C bus. Almost a year and half later, there are some really good news:
The Linux I3C support now has its own Git repository on kernel.org
Besides the first I3C controller driver we wrote for the Cadence I3C Master, Synopsys has contributed a second driver for their I3C master IP: i3c: master: Add driver for Synopsys DesignWare IP. This definitely helped show that there is interest in I3C beyond our contributions, and also helped validate that the subsystem was working fine for a different I3C controller.
I3C subsystem maintainer Boris Brezillon has therefore sent a pull request to get this subsystem merged in the upcoming 4.21 (or 5.0 ?) Linux kernel: [GIT PULL] i3c: Initial pull request, and this pull request has been merged by Linus Torvalds, so the I3C subsystem is now visible in Linus Git tree: drivers/i3c. The merge commit has been done on December 25, so it arrived as a very nice Christmas present!
It has been a long process, but we are proud and happy to have pioneered the support for I3C in the Linux kernel, from the design of the subsystem based on the I3C specifications all the way to its merging in the upstream Linux kernel and the creation of a small (but hopefully growing) community of developers around it.
This year, Bootlin engineer Maxime Chevallier attended the Real-Time Summit, which took place after ELCE in Edinburgh. In a similar fashion to the Linux Media Summit, this was a 1-day conference dedicated to Real-Time topics in the Linux ecosystem, more specifically the Linux Kernel.
The future of Preempt-RT
Real-Time (or should we say, deterministic) behavior in the Linux kernel has been pursued for a long time, the most famous effort being the Preempt-RT patch. As Steven Rostedt announced during his talk at ELCE 2018, the Preempt-RT patch is close to being fully merged in mainline Linux, we can expect to see this happen in 2019.
Some of the maintainers of the Preempt-RT patch were present at the Real-Time summit, including Thomas Gleixner who lead the discussion throughout the day.
This was the occasion to discuss the remaining points to be addressed for Preempt-RT to make it into mainline Linux :
Printk : As Steven Rostedt explained at ELCE 2017, printk is not very real-time friendly. The main issue was worked around, but John Ogness presented his current work of fully redesigning printk’s behaviour.
Thomas Gleixner talked about the current state of softirq handling, which is also a critical point for determinism. They work by “stealing” some irq context time, falling back to ksoftirqd when necessary. This is particularly problematic for networking drivers that heavily rely on softirq.
Peter Zijlstra exposed the different scheduler related issues that needs to be addressed, focusing on SCHED_DEADLINE.
Modeling and analyzing the kernel behavior
All the talks weren’t about the Preempt-RT match merging effort. Daniel Bristot de Oliveira presented his ongoing academic work on modeling the Linux task model. The idea here is to build a formal model that doesn’t take shortcuts or idealize the way tasks are handled in the kernel, so that this can be used as a basis for academic research on topics such as scheduling.
One of the main arguments is that there’s a gap in terms of language and methodology used between kernel developers and the academic world. Daniel explained how he managed to build a huge state-machine representing the task model, and how he uses it now to verify that tasks behave how they should by running trace events in the state machine.
This talk sparked a lot if interesting discussions, for example Peter Zijlstra suggested to compile the state machine into eBPF code and run it live in the kernel.
Julia Lawall was present in the room, and improvised a talk inspired by Daniel’s presentation. She presented DSAC, a static analysis tool dedicated to finding Sleeping in Atomic Context bugs. Julia is involved in the development and use of the coccinelle tool, and explained that it is quickly limited when trying to find that categories of bugs, where sleeping calls can be deeply nested in a call stack protected by spinlocks. Using LLVM, DSAC can analyze complex scenarios with multiple level of nesting and indirect calls to detect SAC bugs. After analyzing the v4.17 kernel sources for only a few hours, the tool was able to detect more than 1000 bugs, 220 of which were confirmed.
The overall technical level of the different talks was high, leading to passionate discussions and suggestions on every topic that was brought during the day.
The Linux Plumbers Conference (LPC) was held a few weeks ago in Vancouver, BC. As always there were several tracks where contributors gave a presentation of on-going or future work, and discussed it with the audience, on specific topics such as thermal, containers, real time, device tree and many more. For the first time at LPC a 2-day networking track took place. As we work on a diversity of networking projects at Bootlin we decided to attend.
The hot topic of the last couple of years in conferences in the network subsystem is XDP, so the conference was not exception. We saw a handful of talks and discussions about the on-going work and support of XDP within the kernel. XDP provides a programmable network data path (using eBPF) in the Linux kernel to process bare metal packets at the lowest point in the network stack. Packets are processed directly in the drivers’ Rx queues, before any allocation happen (such as socket buffers). Facebook is one well known heavy user of this technology (every packet toward Facebook is processed by XDP) and its engineers gavefeedback about how they use XDP and the issues they faced. Other projects and companies are currently evaluating and starting to use XDP as well: we also saw presentations about XDP/eBPF in Open vSwitch, DPDK or kTLS.
While XDP/eBPF was featured in most of the discussions, other interesting topics where brought up. Andrew Lunn gave a presentation about the current need to go beyond 1G copper PHYs for many Linux enabled embedded devices. This was very interesting for us as we used and worked on the technologies used within the Linux kernel to address this, such as Phylink and the SFP bus (we used those when enabling 10G interfaces in the Marvell MacchiatoBin board).
Another presentation caught our attention as the topic was related to what we do at Bootlin. Jesse Brandeburg from Intel talked about the networking hardware offloads and their APIs. He exposed a brief history of the offloads supported by NICs and then showed some issues with the current APIs, where some use cases or behaviors are not clearly defined and sometimes overlap. This is a feeling we share as we experienced it while implementing some of those hardware networking offloads. Jesse’s idea was to open a discussion to come up with better solutions within the next years, as NICs offloading continue to grow.
The Linux Plumbers Conference was very pleasant and well organized. We had the chance to attend the networking track, seeing lots of great cutting-edge topics being discussed; as well as other interesting tracks.
We’d like to thank the conference and track organizers, we had a great time! Videos, slides and papers are now available on the official website or on Youtube.

 Back in August 2017, we wrote in a
Back in August 2017, we wrote in a 