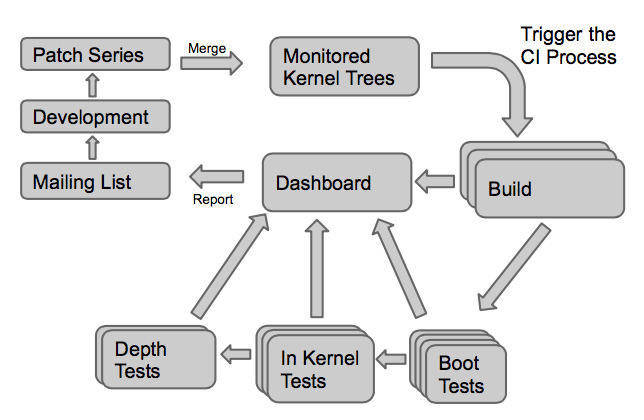
Since April 2016, we have our own automated testing infrastructure to validate the Linux kernel on a large number of hardware platforms. We use this infrastructure to contribute to the KernelCI project, which tests every day the Linux kernel. However, the tests being done by KernelCI are really basic: it’s mostly booting a basic Linux system and checking that it reaches a shell prompt.
However, LAVA, the software component at the core of this testing infrastructure, can do a lot more than just basic tests.
The need for custom tests
With some of our engineers being Linux maintainers and given all the platforms we need to maintain for our customers, being able to automatically test specific features beyond a simple boot test was a very interesting goal.
In addition, manually testing a kernel change on a large number of hardware platforms can be really tedious. Being able to quickly send test jobs that will use an image you built on your machine can be a great advantage when you have some new code in development that affects more than one board.
We identified two main use cases for custom tests:
- Automatic tests to detect regression, as does KernelCI, but with more advanced tests, including platform specific tests.
- Manual tests executed by engineers to validate that the changes they are developing do not break existing features, on all platforms.
Overall architecture
Several tools are needed to run custom tests:
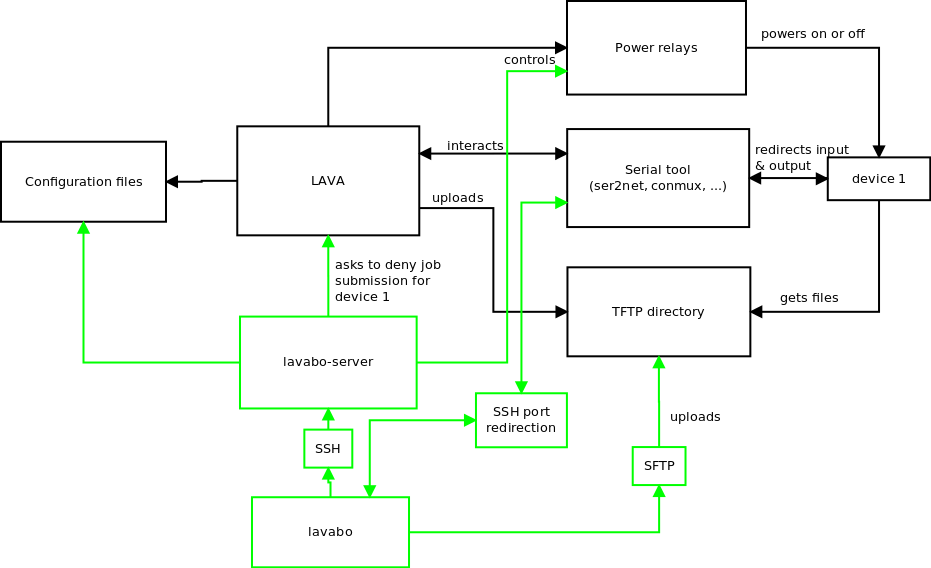
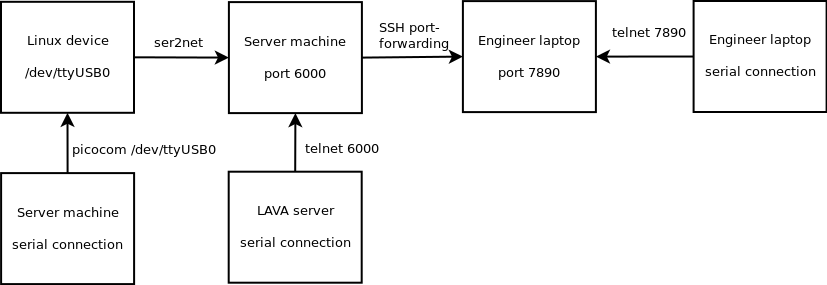
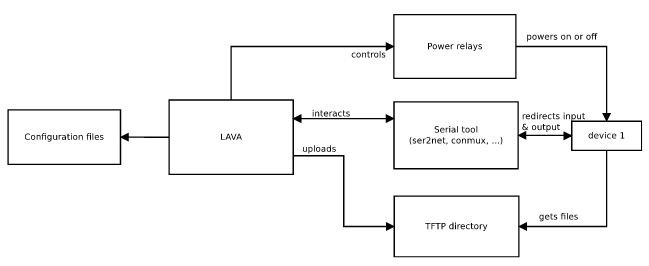
- The LAVA instance, which controls the hardware platforms to be tested. See our previous blog posts on our testing hardware infrastructrure and software architecture
- An appropriate root filesystem, that contains the various userspace programs needed to execute the tests (benchmarking tools, validation tools, etc.)
- A test suite, which contains various scripts executing the tests
- A custom test tool that glues together the different components
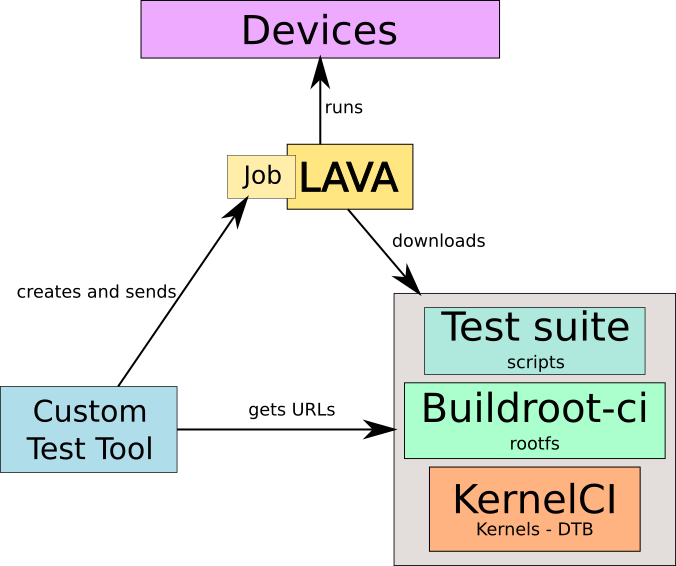
The custom test tool knows all the hardware platforms available and which tests and kernel configurations apply to which hardware platforms. It identifies the appropriate kernel image, Device Tree, root filesystem image and test suite and submits a job to LAVA for execution. LAVA will download the necessary artifacts and run the job on the appropriate device.
Building custom rootfs
When it comes to test specific drivers, dedicated testing, validation or benchmarking tools are sometimes needed. For example, for storage device testing, bonnie++ can be used, while iperf is nice for networking testing. As the default root filesystem used by KernelCI is really minimalist, we need to build our owns, one for each architecture we want to test.
Buildroot is a simple yet efficient tool to generate root filesystems, it is also used by KernelCI to build their minimalist root filesystems. We chose to use it and made custom configuration files to match our needs.
We ended up with custom rootfs built for ARMv4, ARMv5, ARMv7, and ARMv8, that embed for now Bonnie++, iperf, ping (not the Busybox implementation) and other tiny tools that aren’t included in the default Buildroot configuration.
Our Buildroot fork that includes our custom configurations is available as the buildroot-ci Github project (branch ci).
The custom test tool
The custom test tool is the tool that binds the different elements of the overall architecture together.
One of the main features of the tool is to send jobs. Jobs are text files used by LAVA to know what to do with which device. As they are described in LAVA as YAML files (in the version 2 of the API), it is easy to use templates to generate them based on a single model. Some information is quite static such as the device tree name for a given board or the rootfs version to use, but other details change for every job such as the kernel to use or which test to run.
We made a tool able to get the latest kernel images from KernelCI to quickly send jobs without having a to compile a custom kernel image. If the need is to test a custom image that is built locally, the tool is also able to send files to the LAVA server through SSH, to provide a custom kernel image.
The entry point of the tool is ctt.py, which allows to create new jobs, providing a lot of options to define the various aspects of the job (kernel, Device Tree, root filesystem, test, etc.).
This tool is written in Python, and lives in the custom_tests_tool Github project.
The test suite
The test suite is a set of shell scripts that perform tests returning 0 or 1 depending on the result. This test suite is included inside the root filesystem by LAVA as part of a preparation step for each job.
We currently have a small set of tests:
- boot test, which simply returns 0. Such a test will be successful as soon as the boot succeeds.
- mmc test, to test MMC storage devices
- sata test, to test SATA storage devices
- crypto test, to do some minimal testing of cryptographic engines
- usb test, to test USB functionality using mass storage devices
- simple network test, that just validates network connectivity using ping
All those tests only require the target hardware platform itself. However, for more elaborate network tests, we needed to get two devices to interact with each other: the target hardware platform and a reference PC platform. For this, we use the LAVA MultiNode API. It allows to have a test that spans multiple devices, which we use to perform multiple iperf sessions to benchmark the bandwidth. This test has therefore one part running on the target device (network-board) and one part running on the reference PC platform (network-laptop).
Our current test suite is available as the test_suite Github project. It is obviously limited to just a few tests for now, we hope to extend the tests in the near future.
First use case: daily tests
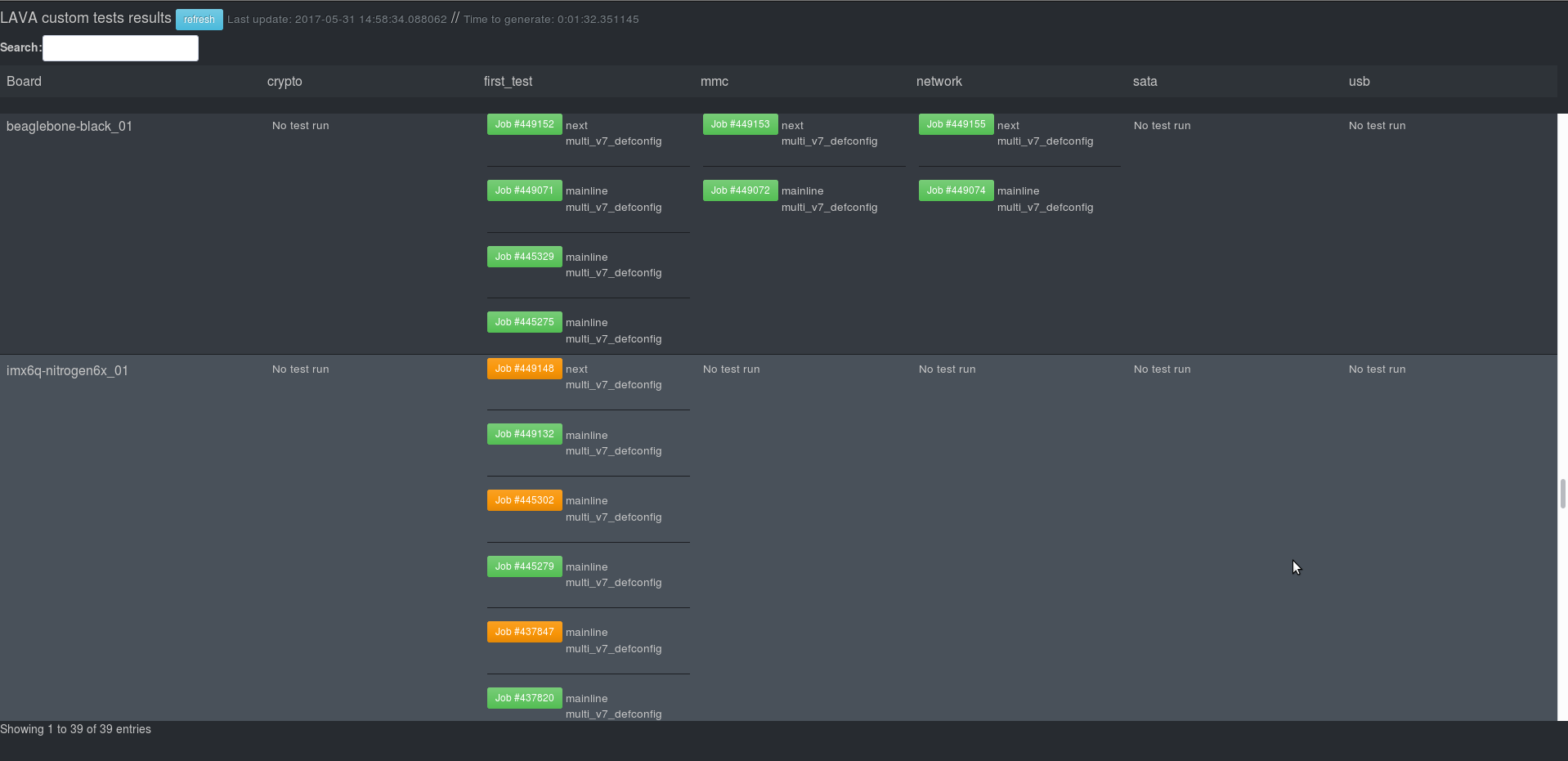
As previously stated, it’s important for us to know about regressions introduced in the upstream kernel. Therefore, we have set up a simple daily cron job that:
- Sends custom jobs to all boards to validate the latest mainline Linux kernel and latest linux-nextli>
- Aggregates results from the past 24 hours and sends emails to subscribed addresses
- Updates a dashboard that displays results in a very simple page
Second use case: manual tests
The custom test tool ctt.py has a simple command line interface. It’s easy for someone to set it up and send custom jobs. For example:
ctt.py -b beaglebone-black -m network
will start the network test on the BeagleBone Black, using the latest mainline Linux kernel built by KernelCI. On the other hand:
ctt.py -b armada-7040-db armada-8040-db -t mmc --kernel arch/arm64/boot/Image --dtb-folder arch/arm64/boot/dts/
will run the mmc test on the Marvell Armada 7040 and Armada 8040 development boards, using the locally built kernel image and Device Tree.
The result of the job is sent over e-mail when the test has completed.
Conclusion
Thanks to this custom test tool, we now have an infrastructure that leverages our existing lab and LAVA instance to execute more advanced tests. Our goal is now to increase the coverage, by adding more tests, and run them on more devices. Of course, we welcome feedback and contributions!