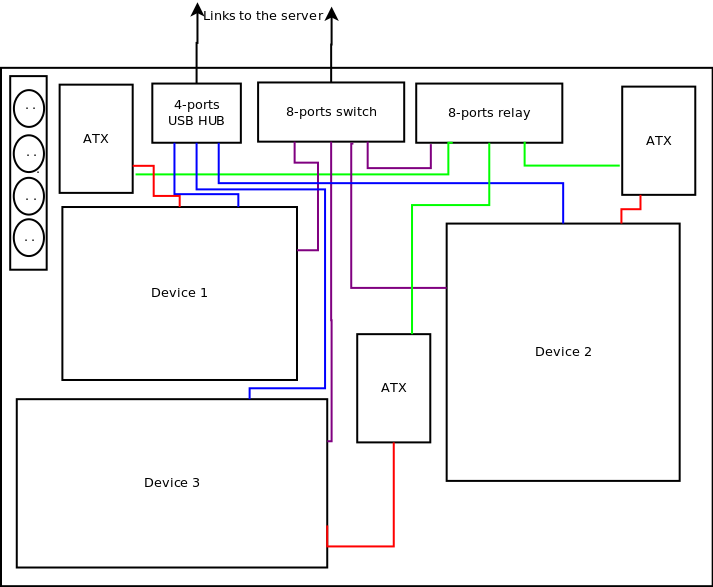
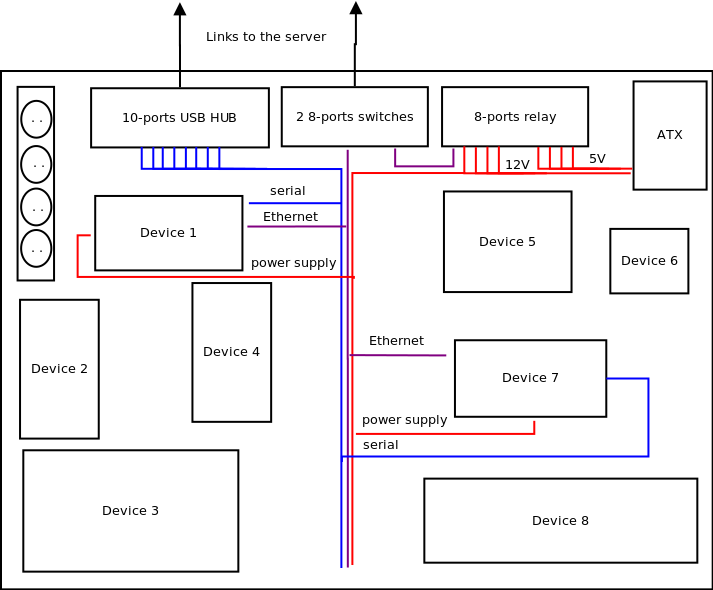
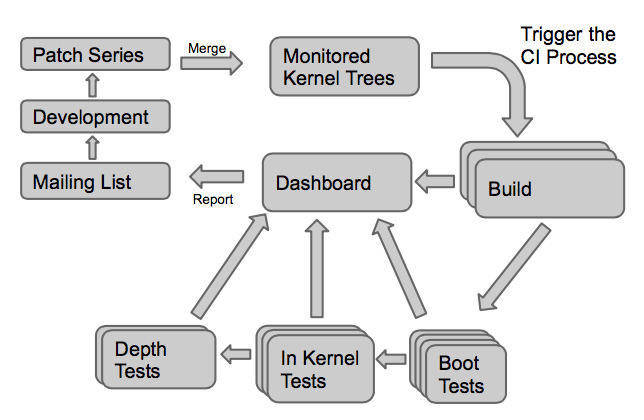
In two previous blog posts, we presented the hardware and software architecture of the automated testing platform we have created to test the Linux kernel on a large number of embedded platforms.
The primary use case for this infrastructure was to participate to the KernelCI.org testing effort, which tests the Linux kernel every day on many hardware platforms.
However, since our embedded boards are now fully controlled by LAVA, we wondered if we could not only use our lab for KernelCI.org, but also provide remote control of our boards to Bootlin engineers so that they can access development boards from anywhere. lavabo was born from this idea and its goal is to allow full remote control of the boards as it is done in LAVA: interface with the serial port, control the power supply and provide files to the board using TFTP.
The advantages of being able to access the boards remotely are obvious: allowing engineers working from home to work on their hardware platforms, avoid moving the boards out of the lab and back into the lab each time an engineer wants to do a test, etc.
User’s perspective
From a user’s point of view, lavabo is used through the eponymous command lavabo, which allows to:
- List the boards and their status
$ lavabo list - Reserve a board for lavabo usage, so that it is no longer used for CI jobs
$ lavabo reserve am335x-boneblack_01 - Upload a kernel image and Device Tree blob so that it can be accessed by the board through TFTP
$ lavabo upload zImage am335x-boneblack.dtb - Connect to the serial port of the board
$ lavabo serial am335x-boneblack_01 - Reset the power of the board
$ lavabo reset am335x-boneblack_01 - Power off the board
$ lavabo power-off am335x-boneblack_01 - Release the board, so that it can once again be used for CI jobs
$ lavabo release am335x-boneblack_01
Overall architecture and implementation
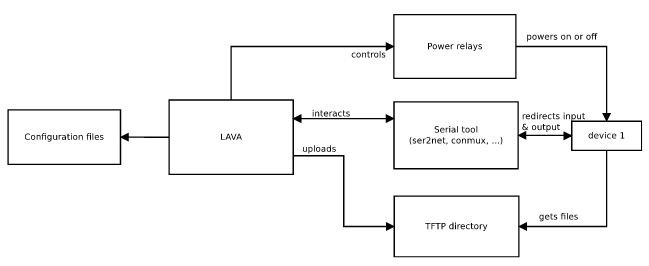
The following diagram summarizes the overall architecture of lavabo (components in green) and how it connects with existing components of the LAVA architecture.
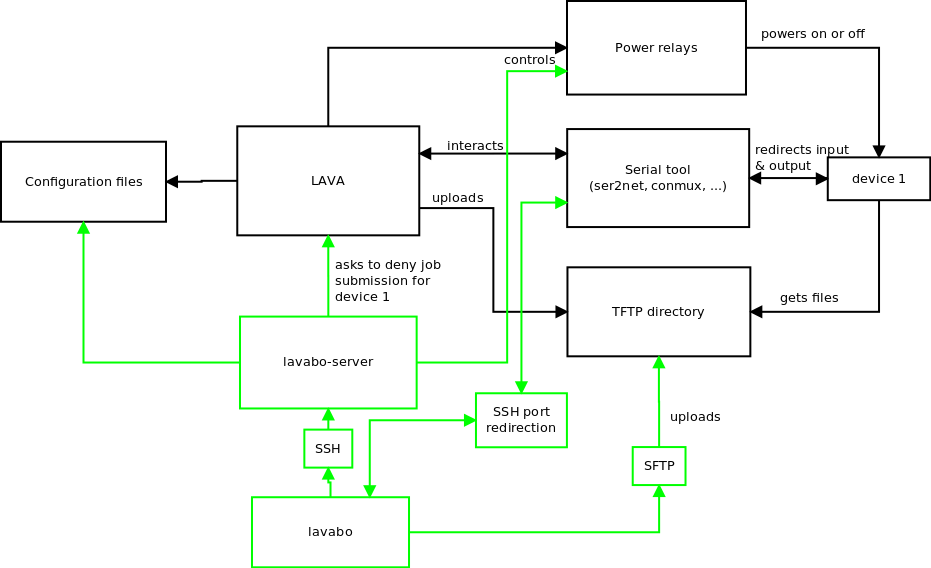
A client-server software
lavabo follows the classical client-server model: the lavabo client is installed on the machines of users, while the lavabo server is hosted on the same machine as LAVA. The server-side of lavabo is responsible for calling the right tools directly on the server machine and making the right calls to LAVA’s API. It controls the boards and interacts with the LAVA instance to reserve and release a board.
On the server machine, a specific Unix user is configured, through its .ssh/authorized_keys to automatically spawn the lavabo server program when someone connects. The lavabo client and server interact directly using their stdin/stdout, by exchanging JSON dictionaries. This interaction model has been inspired from the Attic backup program. Therefore, the lavabo server is not a background process that runs permanently like traditional daemons.
Handling serial connection
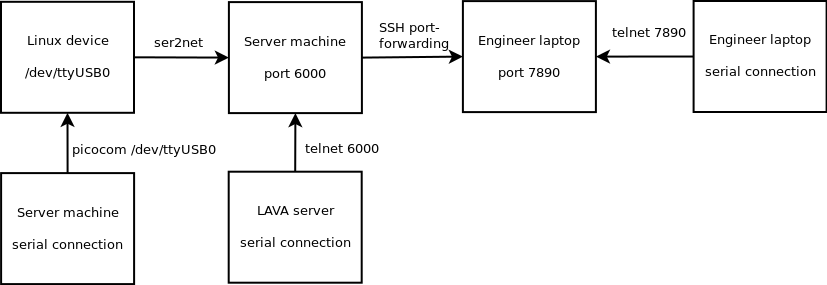
Exchanging JSON over SSH works fine to allow the lavabo client to provide instructions to the lavabo server, but it doesn’t work well to provide access to the serial ports of the boards. However, ser2net is already used by LAVA and provides a local telnet port for each serial port. lavabo simply uses SSH port-forwarding to redirect those telnet ports to local ports on the user’s machine.
Interaction with LAVA
To use a board outside of LAVA, we have to interact with LAVA to tell him the board cannot be used anymore. We therefore had to work with LAVA developers to add endpoints for putting online (release) and for putting offline (reserve) boards and an endpoint to get the current status of a board (busy, idle or offline) in LAVA’s API.
These additions to the LAVA API are used by the lavabo server to make reserve and release boards, so that there is no conflict between the CI related jobs (such as the ones submitted by KernelCI.org) and the direct use of boards for remote development.
Interaction with the boards
Now that we know how the client and the server interact and also how the server communicates with LAVA, we need a way to know which boards are in the lab, on which port the serial connection of a board is exposed and what are the commands to control the board’s power supply. All this configuration has already been given to LAVA, so lavabo server simply reads the LAVA configuration files.
The last requirement is to provide files to the board, such as kernel images, Device Tree blobs, etc. Indeed, from a network point of view, the boards are located in a different subnet not routed directly to the users machines. LAVA already has a directory accessible through TFTP from the boards which is one of the mechanisms used to serve files to boards. Therefore, the easiest and most obvious way is to send files from the client to the server and move the files to this directory, which we implemented using SFTP.
User authentication
Since the serial port cannot be shared among several sessions, it is essential to guarantee a board can only be used by one engineer at a time. In order to identify users, we have one SSH key per user in the .ssh/authorized_keys file on the server, each associated to a call to the lavabo-server program with a different username.
This allows us to identify who is reserving/releasing the boards, and make sure that serial port access, or requests to power off or reset the boards are done by the user having reserved the board.
For TFTP, the lavabo upload command automatically uploads files into a per-user sub-directory of the TFTP server. Therefore, when a file called zImage is uploaded, the board will access it over TFTP by downloading user/zImage.
Availability and installation
As you could guess from our love for FOSS, lavabo is released under the GNU GPLv2 license in a GitHub repository. Extensive documentation is available if you’re interested in installing lavabo. Of course, patches are welcome!
 To meet the size constraints of Bootlin office, we had to make the lab fit in a 100cm wide, 75cm deep and 200cm high space. In order to achieve this, we decided to build the lab as a large home made cabinet, with a number of drawers to easily access, change or replace the boards hosted in the lab. As some of our boards provide PCIe connectors, we needed to provide enough height for each drawer, and after doing a few measurements, decided that a 25cm height for our drawers would be fine. With a total height of 200cm, this gives a maximum of 8 drawers.
To meet the size constraints of Bootlin office, we had to make the lab fit in a 100cm wide, 75cm deep and 200cm high space. In order to achieve this, we decided to build the lab as a large home made cabinet, with a number of drawers to easily access, change or replace the boards hosted in the lab. As some of our boards provide PCIe connectors, we needed to provide enough height for each drawer, and after doing a few measurements, decided that a 25cm height for our drawers would be fine. With a total height of 200cm, this gives a maximum of 8 drawers.