Part of the work on the CFA-10036 and its breakout boards was to write a driver that was using the FIQ mechanism provided by the ARM architecture to bitbang GPIOs on the first GPIO bank of the iMX28 port controller.
Abstract
FIQ stands for Fast Interrupt reQuest, and it is basically a higher priority interrupt. This means that it will always have precedence over regular interrupts, but also that regular interrupts won’t mask or interrupt an FIQ, while an FIQ will mask or interrupt any IRQ.
FIQs are usually not used by the Linux Kernel, yet some infrastructure is available to do everything you need to be able to use the FIQs in a driver. And since Linux only cares about the IRQs, it will never mess with the FIQs, allowing to achieve some hard real time constraints, without having to bother about the masked interrupts.
There are two more things to know about the FIQs. First, FIQs are executed in a dedicated execution mode, and this FIQ mode has 7 dedicated registers, from r8 to r14. This allows to have persistent values between each FIQ handler code, and avoids the overhead of pushing and popping in the handler. The second thing to know is that, unlike the regular IRQ handlers, the FIQ handler has to be written using ARM assembly, mostly because the C compiler won’t produce any code that can use only these r8 to r14 registers.
Practical case
In the CFA-10036 case, we wanted to bitbang a set of GPIOs at a programmable interval with a microsecond accuracy, and from a userspace application. The setup we chose was to make a large memory buffer of instructions available to userspace through mmap, and use a simple consumer/producer setup. An instruction was basically the interval to the next handler firing, which GPIOs values to clear, and which ones to set.
Step 1: Setup a timer
One thing to keep in mind is that basically, we will do many things behind the kernel’s back. So you won’t be able to use the standard kernel framework APIs from the FIQ handler. That means that we won’t be able to use the gpiolib, the regular timer API, etc. So you have to make sure to use either something that is not used at all by the kernel or something the kernel can deal with. The first thing to do then is to register a timer so that we can generate our FIQ on a regular basis. Here, we chose the third iMX28 timer, that is the first timer not used by the kernel. Of course, since it is device dependent and not using the kernel’s API, we had to do the timer initialization by hand in our driver.
We obviously made it generate an interrupt when it expires, and then had to poke into the iMX28 interrupt controller to generate a FIQ from this interrupt. How to achieve this is once again dependent on the hardware, and some architectures provide functions to do so (s3c24xx_set_fiq for Samsung’s Exynos, mxc_set_irq_fiq for Freescale’s IMX, etc.) while some others don’t, like it was the case for iMX28 (which is part of the MXS architecture), so we had to do it by hand once again in our driver.
Once this is done, we now have a timer that generates an FIQ on a regular basis. The second step will obviously be to register our handler for this FIQ.
Step 2: Register our handler
Registering an FIQ handler is actually quite simple. The first thing to do is actually to call the claim_fiq function, that mostly makes sure no other FIQ handler has already been registered.
The next step is to register your FIQ handler. This is done with the set_fiq_handler function. This function takes a pointer to the handler and the size of the handler code as argument, to basically memcpy your handler directly into the interrupt vector.
Most of the time, we would have something like below in our assembly code, and compute the handler size by the difference between the two labels.
my_handler:
handler code
my_handler_end:
Beware that it can get nasty, especially when you use a numeric constant that will get stored in a literal pool (for example when storing large variables into a register using LDR), if you don’t pay attention, the literal pool will be stored outside of the bounds you asked to copy, resulting in the value you use in the actual FIQ handler being garbage. We can also pre-set some register values that you will find in FIQ mode, typically to pass arguments to your handler, using the set_fiq_regs function.
The last step is obviously to enable the FIQ, using the enable_fiq function.
Once this is done, we have the basic infrastructure to process the data that will come from the shared buffer.
Step 3: Allocate the instruction buffer and share it
We needed a pretty large instruction buffer to share with userspace. We wanted to store about 1 million instructions in the buffer, each instruction taking 12 bytes (3 unsigned long integers), which makes around 12 MiB.
The usual allocation mechanism couldn’t be used, because __get_free_pages can only allocate up to 512 pages. Each page on ARM being of 4 KiB, this function is thus limited to 2 MiB.
So we chose to use CMA (Contiguous Memory Allocator) that was introduced in the 3.4 kernel, and is used precisely to allocate large chunk of contiguous memory. It achieves this by allocating a given size of movable pages at boot time, that will be used by the kernel as long as no one needs them, and will be reclaimed when a driver needs them. CMA is also used directly through the regular DMA API, so we’re in known territory.
The first thing to do to use CMA is to declare the memory region we want to reserve for our device in the device tree (we have been using the “Device tree support for CMA” patchset).
As you may know, the device tree is for hardware description and the CMA shouldn’t be in it at all, since it doesn’t describe the hardware in itself, but how we need to allocate the memory for a given piece of hardware. The chosen node is here exactly for that, since it will hold all the things the system needs, but doesn’t describe hardware. A similar case is the kernel command line. In our case, we add a subnode to chosen, with which amount of memory we should pre-allocate (0xc00000, which is 12 MiB, in our case), at which kernel address (0 in our case, since we basically don’t care about the base address of the buffer, we just want it to be there), and which device should use it.
Then, in our driver, we only need to call dma_alloc_coherent from our driver, and that’s it.
Now, we need to share this memory through mmap. This wouldn’t be a big deal, except for the caches. Indeed, the ARMv5 caches are virtually tagged, resulting in cache coherency problem when using two different virtual addresses pointing to the same physical address, which is exactly the situation we will be in.
We thus need to disable the cache on this particular mapping. This is done through a flag set with the pgprot_noncached function, that sets the page protection flags before calling the remap_pfn_range function in the mmap driver hook.
This should be ok by now, and you should be able to use the data inside the buffer from both sides now.
Step 4: Actual Results
We here tried to generate a 50kHz square waveform by bitbanging the GPIOs both using a FIQ and using a regular IRQs, and here is the result (to emulate some load on the system, a dd if=/dev/zero of=/file was run when the captures were taken).
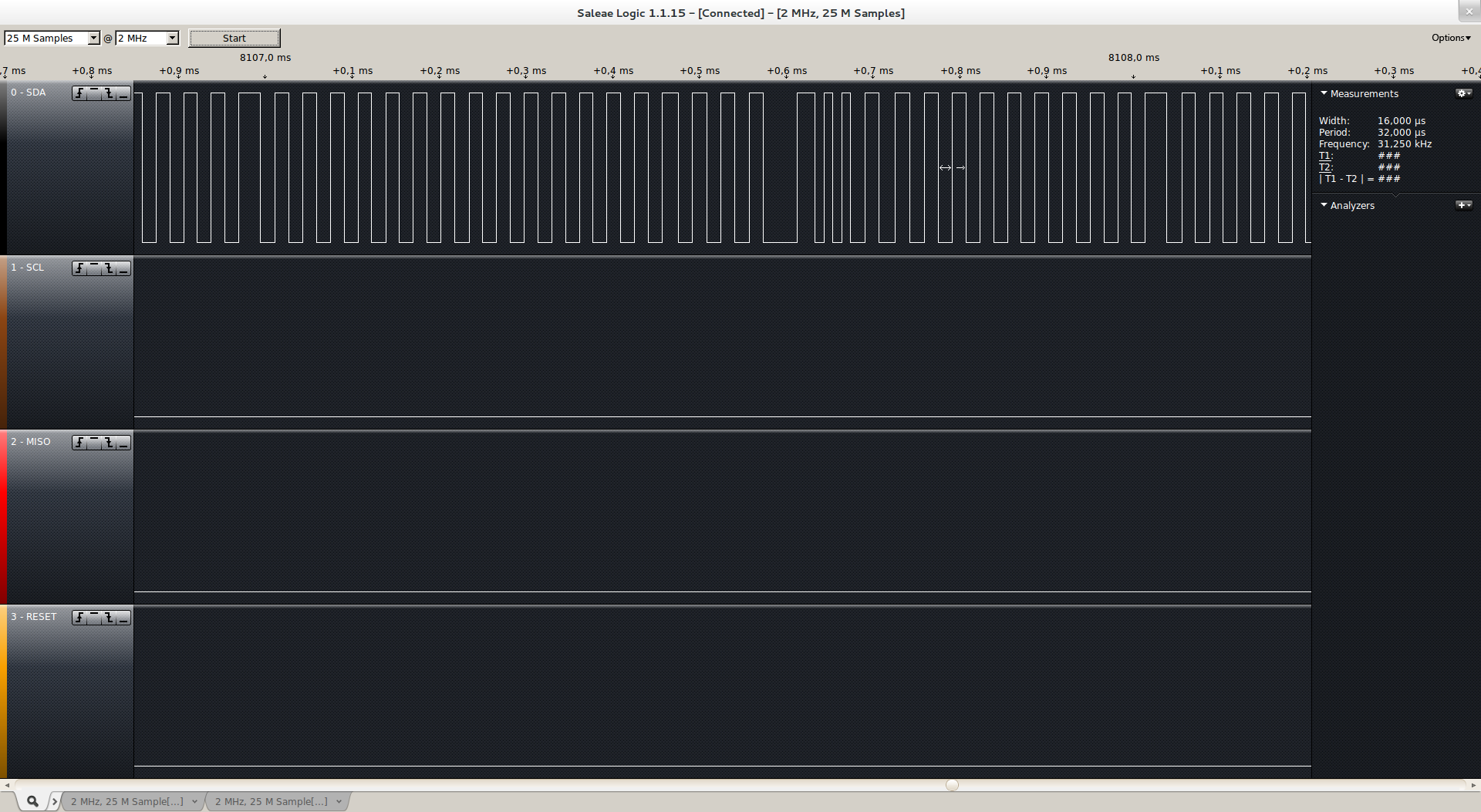
This is using regular IRQs. We can notice several thing wrong about this. The first one is pretty obvious, since we have a lot of jitter. The next one is that even though we requested a interval between each timer firing of 10microseconds, we here see that we are more around 16us, with quite a lot of latency.
Now, here is what we get with an FIQ:
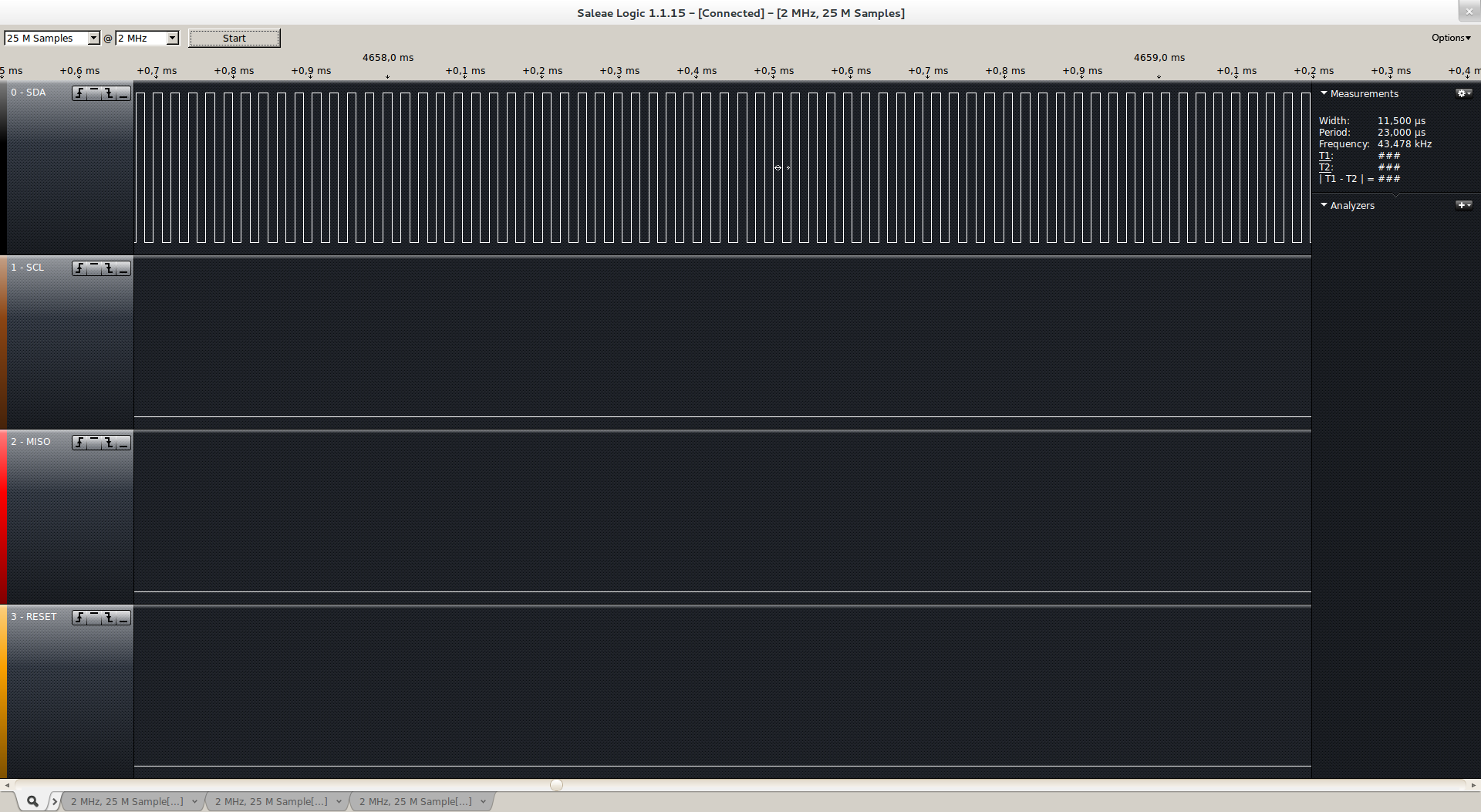
We can see that there’s no longer any jitter, the 50kHz square waveform we requested is almost perfectly output by our FIQ handler. We can notice however that there is still a constant ~1us latency, presumably because we had to reprogram the timer from our handler.
Final Words
Working on this FIQ thing has been really great, mostly because it involved several things I wasn’t used to, like CMA, or to make sure the kernel could deal with something changing behind its back. For example, we had to change slightly the imx28 gpio driver, because it was keeping an internal cache of the GPIO values it previously set, resulting in a pretty nasty behaviour when changing a GPIO value from the FIQ, and then controlling another one through the regular GPIO interface.
The application for this was to generate waveforms sent to stepper drivers, to control a 3D printer from the CFA-10036. You can watch the end result of all this work on Crystalfontz‘ Youtube channel, and especially on this video:
Finally, we can conclude that the FIQ can be an effective way to achieve near-real-time latencies, on a vanilla kernel without any RT patches.
Of course, you can find the whole code on Crystalfontz Github, most notably the driver, the handler and a small application demo for it.
Here is another resource on this topic (Alessandro Rubini at ELCE 2009): http://elinux.org/images/2/27/0910-elce-fiq.pdf
I also used FIQs a few weeks ago on a Marvell 6182. I read GPIO bank at 6Mhz (reading was driven by an exernal clock). It was a proof of concept, so not sure it would work all the time, but I was also impressed by the result.
Hello, I am using Linux kernel 4.9.11 and imx6q(dual core, arm cortex A9). The FIQ is handled as NMI and the arm mode is system mode so FIQ can be handled as normal IRQ as normal IRQ is also running in system mode. The interrupt controller is a GIC-v1 in the imx6q itself.
But this only work in I select nosmp in Linux command line, that mean only cpu0 is up.
with 2 cores, the system cannot start after the second cpu is bring up.
It bas no problem if I do not use FIQ.