Today, we are pleased to announce the initial release of the Elixir Cross-Referencer, or just “Elixir”, for short.
What is Elixir?
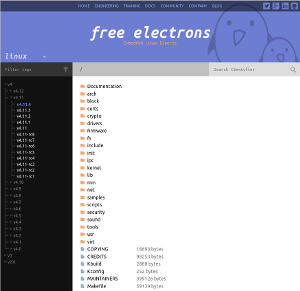 Since 2006, we have provided a Linux source code cross-referencing online tool as a service to the community. The engine behind this website was LXR, a Perl project almost as old as the kernel itself. For the first few years, we used the then-current 0.9.5 version of LXR, but in early 2009 and for various reasons, we reverted to the older 0.3.1 version (from 1999!). In a nutshell, it was simpler and it scaled better.
Since 2006, we have provided a Linux source code cross-referencing online tool as a service to the community. The engine behind this website was LXR, a Perl project almost as old as the kernel itself. For the first few years, we used the then-current 0.9.5 version of LXR, but in early 2009 and for various reasons, we reverted to the older 0.3.1 version (from 1999!). In a nutshell, it was simpler and it scaled better.
Recently, we had the opportunity to spend some time on it, to correct a few bugs and to improve the service. After studying the Perl source code and trying out various cross-referencing engines (among which LXR 2.2 and OpenGrok), we decided to implement our own source code cross-referencing engine in Python.
Why create a new engine?
Our goal was to extend our existing service (support for multiple projects, responsive design, etc.) while keeping it simple and fast. When we tried other cross-referencing engines, we were dissatisfied with their relatively low performance on a large codebase such as Linux. Although we probably could have tweaked the underlying database engine for better performance, we decided it would be simpler to stick to the strategy used in LXR 0.3: get away from the relational database engine and keep plain lists in simple key-value stores.
Another reason that motivated a complete rewrite was that we wanted to provide an up-to-date reference (including the latest revisions) while keeping it immutable, so that external links to the source code wouldn’t get broken in the future. As a direct consequence, we would need to index many different revisions for each project, with potentially a lot of redundant information between them. That’s when we realized we could leverage the data model of Git to deal with this redundancy in an efficient manner, by indexing Git blobs, which are shared between revisions. In order to make sure queries under this strategy would be fast enough, we wrote a proof-of-concept in Python, and thus Elixir was born.
What service does it provide?
First, we tried to minimize disruption to our users by keeping the user interface close to that of our old cross-referencing service. The main improvements are:
- We now support multiple projects. For now, we provide reference for Linux, Busybox and U-Boot.
- Every tag in each project’s git repository is now automatically indexed.
- The design has been modernized and now fits comfortably on smaller screens like tablets.
- The URL scheme has been simplified and extended with support for multiple projects. An HTTP redirector has been set up for backward compatibility.
Among other smaller improvements, it is now possible to copy and paste code directly without line numbers getting in the way.
How does it work?
Elixir is made of two Python scripts: “update” and “query”. The first looks for new tags and new blobs inside a Git repository, parses them and appends the new references to identifiers to a record inside the database. The second uses the database and the Git repository to display annotated source code and identifier references.
The parsing itself is done with Ctags, which provides us with identifier definitions. In order to find the references to these identifiers, Elixir then simply checks each lexical token in the source file against the definition database, and if that word is defined, a new reference is added.
Like in LXR 0.3, the database structure is kept very simple so that queries don’t have much work to do at runtime, thus speeding them up. In particular, we store references to a particular identifier as a simple list, which can be loaded and parsed very fast. The main difference with LXR is that our list includes references from every blob in the project, so we need to restrict it first to only the blobs that are part of the current version. This is done at runtime, simply by computing the intersection of this list with the list of blobs inside the current version.
Finally, we kept the user interface code clearly segregated from the engine itself by making these two modules communicate through a Unix command-line interface. This means that you can run queries directly on the command-line without going through the web interface.
What’s next?
Our current focus is on improving multi-project support. In particular, each project has its own quirky way of using Git tags, which needs to be handled individually.
At the user-interface level, we are evaluating the possibility of having auto-completion and/or fuzzy search of identifier names. Also, we are looking for a way to provide direct line-level access to references even in the case of very common identifiers.
On the performance front, we would like to cut the indexation time by switching to a new database back-end that provides efficient appending to large records. Also, we could make source code queries faster by precomputing the references, which would also allow us to eliminate identifier “bleeding” between versions (the case where an identifier shows up as “defined in 0 files” because it is only defined in another version).
If you think of other ways we could improve our service, don’t hesitate to drop us a feature request or a patch!
Bonus: why call it “Elixir”?
In the spur of the moment, it seemed like a nice pun on the name “LXR”. But in retrospect, we wish to apologize to the Elixir language team and the community at large for unnecessary namespace pollution.
I tried to get it running in my Debian with the lasted linus source, but I didn’t understand how to do it.
Can you post a step-by-step to get it working ?
There’s an installation guide on https://github.com/bootlin/elixir/blob/master/README.md
Hope it helps.
Michael.
Hi,
No didn’t help, I tried that.
I will post here all the steps that I did.
Thanks
chapeau !
Hi ! Great work, browsing linux code is easier than ever 😉
However I have a small issue with the new system: I can’t copy/paste from it. When I select some part of a C file and copy it (either ctrl+c in my browser, or selecting with the mouse on Linux), the paste (either with ctrl+c in my browser or middle click in Linux) is not indented correctly anymore, and is a pain to read.
I tried with firefox and chrome, both have the same behavior.
Could it possible to fix the indenting of copier code ?
Hi,
Thank you for the issue report.
Would you mind filing an issue on the GitHub project page, please?
https://github.com/bootlin/elixir/issues
That will make things easier to track.
Thank you in advance,
Cheers,
Michael.
Right away !
After a couple of new tests, I don’t have issues anymore (tested with firefox/gedit/vim).. I had some updates in ubuntu this morning, maybe it fixed the issue ? So I have nothing more to report.
Great job anyway, I really like elixir !
The previous version of the tool allowed to compare (diff) between to version of the kernel code; are you planning to support this functionality in the new version?
+1 for this. The diff was an exceedingly important feature of the old version when trying to understand how some driver had changed.
+1
missing the “diff” support in the new tool.
+1
Great job with the new tool – really sleek and fast.
However I was using LXR for the diff between the kernel versions to evaluate and create reports for the amount of work involved in backporting fixes. Now I cannot do this in an expedient way.
Would it be difficult to bring back the old LXR as an alternative kernel browsing tool on a secondary page (leave the Elixir as the main visible tool here) until this feature will be available in Elixir?
Hi Radu,
Indeed, you’re not the first one to ask for this feature.
Unfortunately, until we can implement it in Elixir, this will be too much work for us
to manage two versions (LXR and Elixir) at once. You may make your own installation
though…
Cheers,
Michael.
Agree… The diff feature was probably my main use-case for LXR. Was much more straightforward than having to download several full trees from linux.org and diffing them locally.
+1
missing the “diff”
Hi, if I’m going to setup a Elixir service to index Linux kernel, what is the hardware requirement? Like how much disk space do I need and how much memory at least?
Hi Kai,
I added details on this topic on https://github.com/bootlin/elixir/blob/master/README.md
Great tool!
Some suggestions:
* make it possible to search for CONFIG options, i.e. find the matching Kconfig file
* make it possible to search for all struct names (sometimes they are linked, sometimes not)
Hi,
Yes, supporting the Kconfig language is on our todo list, and would be very useful indeed 🙂
About struct members, would you have an example?
For both items, would you mind filing an issue / improvement on GitHub? This would help with tracking…
Thanks,
Michael.
Hi.
I’m a big fan of the Elixir browseable Linux source code. Thanks for this resource!
I’d like to use this for my own source code repos but I’m unclear on how to make use of the Dockerfile – I’m fairly new to Docker but I see it’s utility and want to use it.
Here are the steps I’m using for Docker:
1. docker build -t my_source –build-arg GIT_REPO_URL=https://github.com/altera-opensource/linux-socfpga
2. docker run -it my_source bash
Then I should be able to use the script commands in the README.md file, right? This doesn’t seem to be working for me.
Thanks again for a great resource!